



Open-source datasets have significantly democratized access to high-quality data, lowering the barriers of entry for developers and researchers to train cutting-edge generative AI models. By providing free access to diverse, high-quality, and well-curated datasets, open-source datasets enable the open-source community to train models at or close to the frontier, facilitating the rapid advancement of AI.
Zyphra makes AI systems more accessible, exploring the frontiers of performance through cutting-edge architectures, and advancing the study and understanding of powerful models.
To achieve its vision, the Zyphra team has been collaborating closely with the NVIDIA NeMo Curator team to create Zyda-2, an open, high-quality, pretraining dataset comprising an impressive 5T tokens in English, 5x the size of Zyda-1. This dataset encompasses a vast range of topics and domains and ensures a high level of diversity and quality, which are critical for training robust and competitive models such as Zamba.
Train highly accurate LLMs with Zyda-2
Zyda-2 is ideal for general high-quality language model pretraining that is especially focused on language proficiency, as opposed to code and math that require additional specialized datasets. This is because Zyda-2 possesses the strengths of the top existing datasets while improving on their weaknesses.
Figure 1 shows the Zyda-2 outperforms existing state-of-the-art open-source language modeling datasets in aggregate evaluation scores. The Zyphra team performed this ablation study using the Zamba2-2.7B parameter model and the aggregate score is a mean of MMLU, Hellaswag, Piqa, Winogrande, Arc-Easy, and Arc-Challenge.
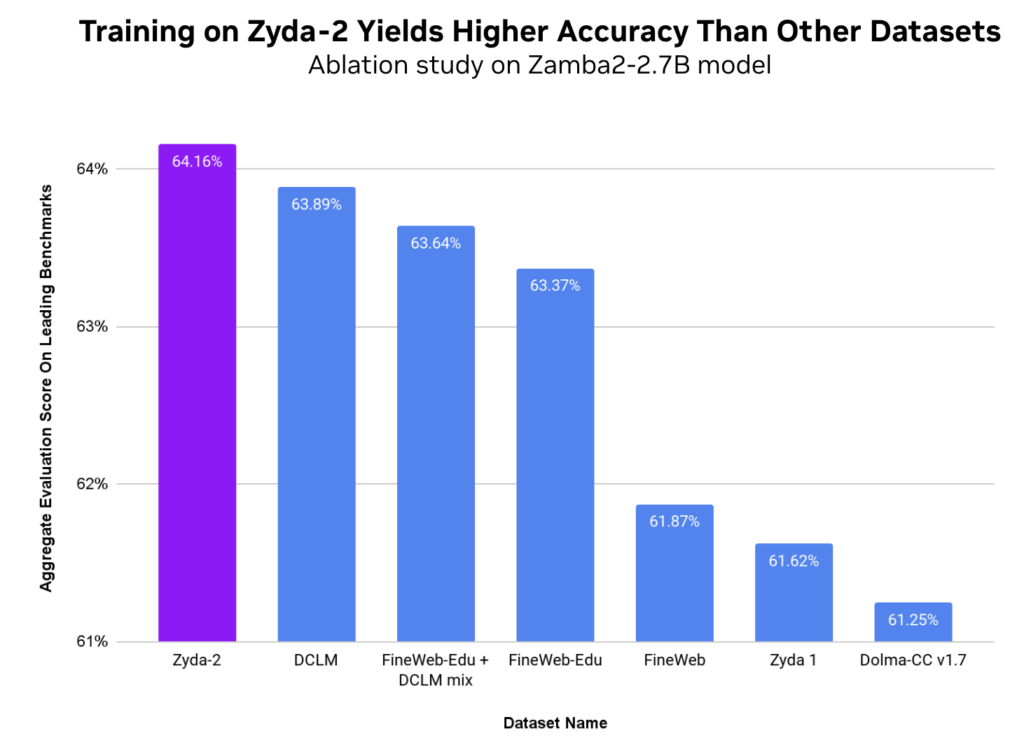
Zyphra’s training methodology is to focus on maximizing model quality and efficiency at a given memory and latency budget, both for on-device and cloud deployments. The Zyphra team has also trained Zamba2-7B, a 7B-parameter hybrid model on an early version of the Zyda-2 dataset that has outperformed other frontier models on the leaderboard, testifying to the strength of this dataset at scale.
Access the Zamba2-7B packaged as an NVIDIA NIM microservice for easy deployment on any GPU-accelerated system or through industry-standard APIs.
Building blocks of Zyda-2
Zyda-2 combines the existing sources of open high-quality tokens such as DCLM, FineWeb-edu, Dolma, and Zyda-1. It performs robust filtering and cross-deduplication to improve the performance of each dataset alone. Zyda-2 combines the best elements of these datasets with many high-quality educational samples for logical reasoning and factual knowledge, while its other Zyda-1 component provides more diversity and variety and excels at more linguistic and writing tasks.
In short, while each component dataset has its own strengths and weaknesses, the combined Zyda-2 dataset can fill these gaps. The total training budget to obtain a given model quality is reduced compared to the naive combination of these datasets through the use of deduplication and aggressive filtering.
Here’s how Zyphra has used NVIDIA NeMo Curator to build its data processing pipelines and improve the quality of the data.
NeMo Curator’s role In creating the dataset
NeMo Curator is a GPU-accelerated data curation library that improves generative AI model performance by processing large-scale, high-quality datasets for pretraining and customization.
Yury Tokpanov, dataset lead at Zyphra said, “NeMo Curator played a crucial role in bringing the dataset to market faster. By using GPUs to accelerate the data processing pipelines, our team reduced the total cost of ownership (TCO) by 2x and processed the data 10x faster (from 3 weeks to 2 days). Because of the quality improvement in data, It was worth it for us to stop training, do processing with NeMo Curator, and train a model on the processed dataset.”
To accelerate workflows on GPUs, NeMo Curator uses RAPIDS libraries such as cuDF, cuML, and cuGraph and scales to 100+ TB of data. High-quality data is crucial for improving the accuracy of generative AI models. To continually enhance data quality, NeMo Curator supports several techniques such as exact, fuzzy, and semantic deduplication, classifier models, and synthetic data generation.
With NeMo Curator, Zyphra has been able to streamline the process of data pre-processing, cleaning, and organization, ultimately leading to a dataset that is well-suited for developing advanced language models.
NeMo Curator’s features, including deduplication and quality classification, were essential for distilling the raw component datasets of Zyda-2 into the highest-quality subset to be used for training. The fuzzy deduplication techniques based on LSH minhashing included in NeMo Curator helped Zyphra’s team find and remove 13% of data from the DCLM dataset as duplicates found in other datasets.
The quality classifier model was also used to assess the Dolma-CC and Zyda-1 component data subsets, marking 25% and 17% of them respectively as high quality. Zyda’s team has found that including only the high-quality subset in the final dataset improved performance.
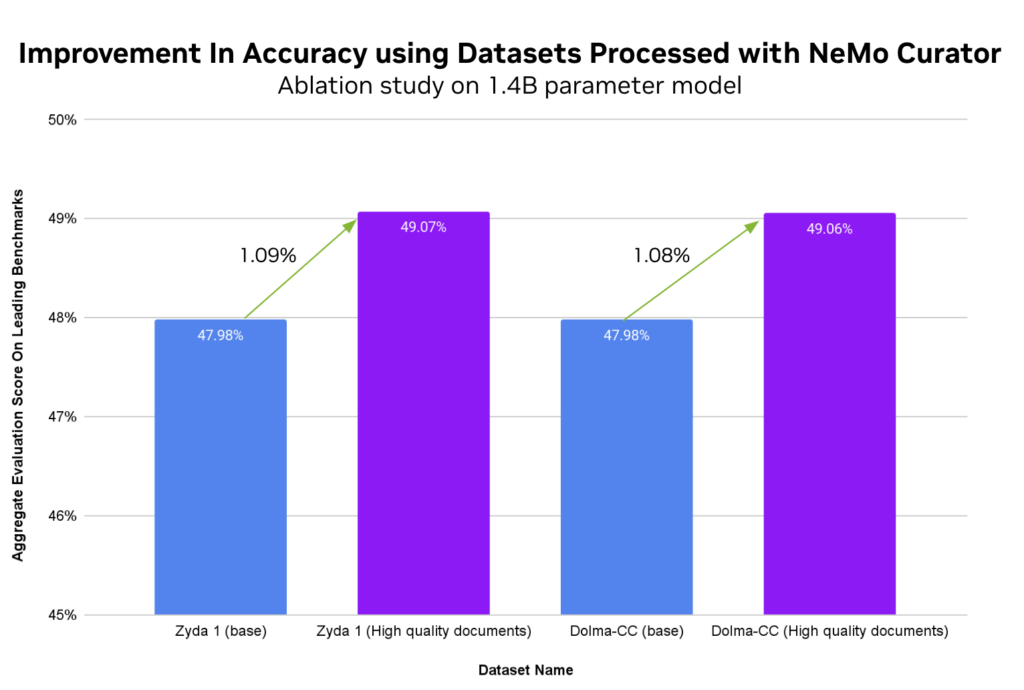
Figure 2 represents the improvement in accuracy when trained on high-quality subsets of the original datasets. The chart shows training on 50B tokens of the full Zyda and Dolma datasets compared to training only those documents labeled ‘high’ in the quality classifier from NeMo Curator.
Get started
Download the Zyda-2 dataset directly from Hugging Face and train higher-accuracy models. It comes with an ODC-By license which enables you to train on or build off of Zyda-2 subject to the license agreements and terms of use of the original data sources.
For more information, see the Zyda-2 tutorial on the /NVIDIA/NeMo-Curator GitHub repo. You can also try the Zamba2-7B NIM microservice for free directly from the NVIDIA API Catalog.
Train Highly Accurate LLMs with the Zyda-2 Open 5T-Token Dataset Processed with NVIDIA NeMo Curator