



AI is no longer just about generating text or images—it’s about deep reasoning, detailed problem-solving, and powerful adaptability for real-world applications in business and in financial, customer, and healthcare services.
Available today, the latest Llama Nemotron Ultra reasoning model from NVIDIA delivers leading accuracy among open-source models across intelligence and coding benchmarks while increasing the levels of compute efficiency. You can find the model, weights, and training data on Hugging Face to adopt AI for everything from research assistants and coding copilots to automated workflows.
NVIDIA Llama Nemotron Ultra excels at advanced science coding and math benchmarks
Llama Nemotron Ultra is redefining what AI can achieve in scientific reasoning and coding and math benchmarks. Post-trained for complex reasoning, human-aligned chat, retrieval-augmented generation (RAG), and tool use, the model is built for real-world enterprise needs—from copilots and knowledge assistants to automated workflows—with the depth and flexibility required for high-impact AI.
Llama Nemotron Ultra builds on Meta Llama 3.1 and is refined using commercial and synthetic data plus advanced training techniques. Designed for agentic workflows, it delivers strong reasoning capabilities and accessible, high-performance AI while keeping costs down. To support broader development of reasoning models, NVIDIA has open-sourced two high-quality training datasets used in post-training.
These resources provide the community with a head start in building high-performing, cost-efficient models. They were proven effective by the NVIDIA team that recently earned first place at the @KaggleAI Mathematical Olympiad for a competitive reasoning benchmark. The data, technology, and insights were then applied to Llama Nemotron Ultra. The next sections look at these three benchmarks in detail.
GPQA Diamond benchmark
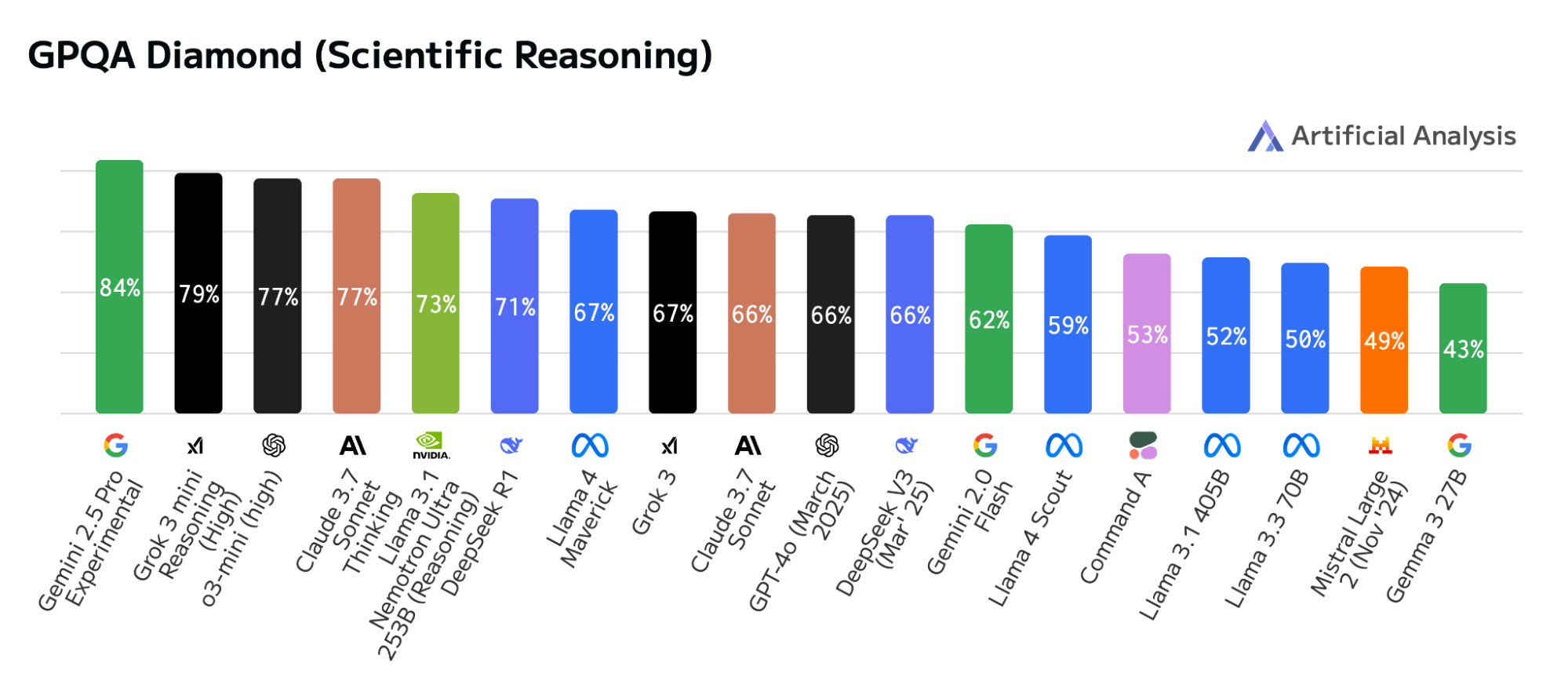
As shown in Figures 1, 2, and 3, the Llama Nemotron Ultra reasoning model outperforms other open models in a scientific reasoning benchmark. The GPQA Diamond benchmark consists of 198 meticulously crafted questions across biology, physics, and chemistry, developed by PhD-level experts.
These graduate-level problems demand multistep reasoning and deep comprehension, far beyond rote memorization or surface-level inference. While humans who hold PhDs average around 65% accuracy on this challenging subset, Llama Nemotron Ultra has set a new standard—achieving 76% and establishing itself as the leading open model in scientific reasoning. This result can be found on the Artificial Analysis and Vellum leaderboards.


LiveCodeBench benchmark
As shown in Figure 4, 5, and 6, in addition to excelling in advanced science benchmarks, Llama Nemotron Ultra has achieved remarkable performance on LiveCodeBench—a robust benchmark designed to assess real-world coding capabilities. LiveCodeBench focuses on broader coding tasks such as code generation, debugging, self-repair, test output prediction, and execution.
Each problem in LiveCodeBench is date-stamped to ensure fair, out-of-distribution evaluation. By emphasizing real problem-solving over code output, it tests true generalization. This result can be found on the Artificial Analysis and GitHub – LiveCodeBench leaderboards.


AIME benchmark
Llama Nemotron Ultra also exceeds other open models in the AIME benchmark, which is often used as a benchmark to evaluate mathematical reasoning abilities. Check out the live LLM leaderboard.

Open datasets and tools
One of Llama Nemotron’s most critical contributions is its open design philosophy. NVIDIA released the model itself as well as two core, commercially viable datasets that helped shape its reasoning skills, which are now trending at the top of Hugging Face Datasets.
OpenCodeReasoning Dataset: Encompasses over 735K Python samples derived from 28K unique questions, sourced from popular competitive programming platforms. Designed specifically for supervised fine-tuning (SFT), this dataset enables enterprise developers to distill advanced reasoning capabilities into their models. By leveraging OpenCodeReasoning, organizations can enhance the problem-solving proficiency of AI systems, leading to more robust and intelligent coding solutions.
Llama-Nemotron-Post-Training Dataset: Synthetically generated using publicly available and open models, including Llama, the Nemotron family, the Qwen family, and DeepSeek-R1 models. Designed to enhance a model’s performance across key reasoning tasks, this dataset is ideal for improving capabilities in math, coding, general reasoning, and instruction following. It offers a valuable resource for fine-tuning models to better understand and respond to complex, multistep instructions, helping developers build more capable and aligned AI systems.
By making these datasets free on Hugging Face, NVIDIA aims to democratize the training of reasoning models. Startups, research labs, and enterprises can now benefit from the same resources used by NVIDIA internal teams, accelerating the broader adoption of agentic AI—AI that can autonomously reason, plan, and act within sophisticated workflows.
Enterprise-ready features: Speed, accuracy, and flexibility
Llama Nemotron Ultra is a commercially viable model and can be used in a variety of agentic AI use cases—including coding copilots, customer service chatbots, autonomous research agents, and task-oriented assistants. Its strong performance in scientific reasoning and coding benchmarks makes it a powerful foundation for real-world applications that demand accuracy, adaptability, and multistep problem solving.
Llama Nemotron Ultra offers best-in-class model accuracy while providing leading throughput in the open-reasoning model class. Its efficiency (throughput) directly translates to savings. Using a Neural Architecture Search (NAS) approach, we greatly reduce the model’s memory footprint while retaining its performance, enabling larger workloads, and fewer GPUs to run the model in a data center environment.
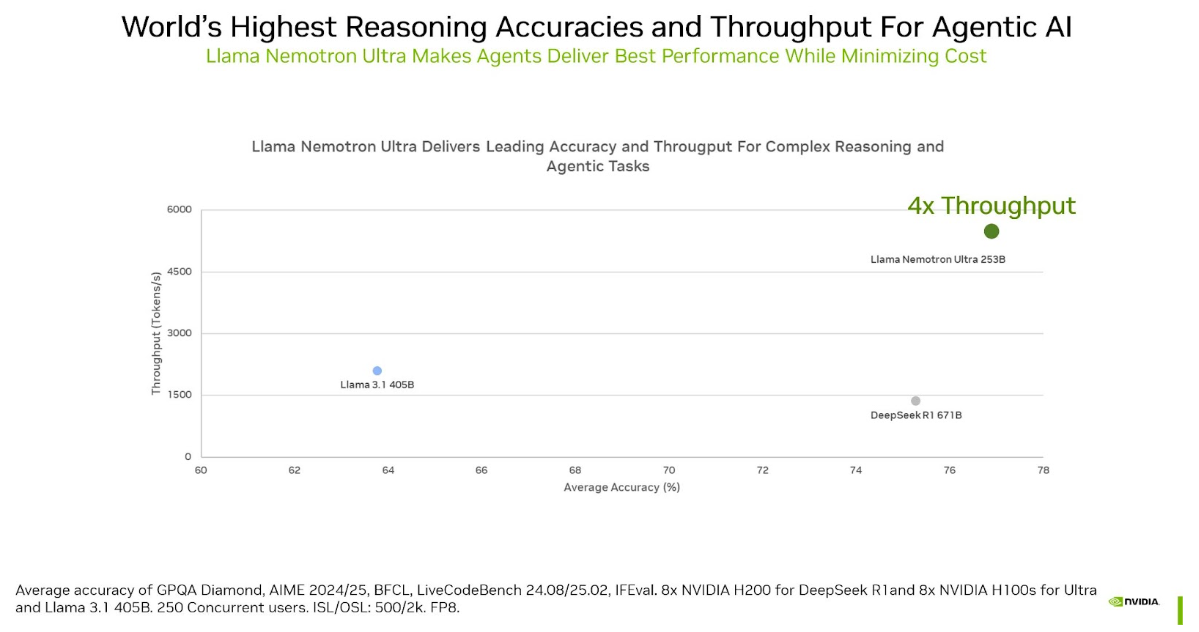
After this process, the model underwent a comprehensive post-training pipeline including supervised fine-tuning and reinforcement learning (RL) to augment the model’s capabilities, enabling it to excel at both reasoning and non-reasoning tasks. The model supports reasoning ‘On’ and ‘Off’ functionality, allowing enterprises to activate reasoning only when needed and reducing overhead for simpler, non-agentic tasks.
Get started
NVIDIA has packaged Llama Nemotron Ultra as an NVIDIA NIM inference microservice, optimized for high throughput and low latency. NVIDIA NIM delivers seamless, scalable AI inferencing, on-premises or in the cloud, leveraging industry-standard APIs.
- Try the Llama Nemotron Ultra NIM directly from your browser
- Download the Llama Nemotron Ultra model from Hugging Face
- To train custom reasoning models for your use case, download the OpenCodeReasoning Dataset and Llama-Nemotron-Post-Training Dataset and customize
Related resources
- GTC session: Building Scalable Data Flywheels for Continuously Improving AI Agents
- NGC Containers: Llama-3.1-Nemotron-70B-Instruct
- NGC Containers: nemotron-4-340b-instruct
- NGC Containers: Nemotron-4-340B-Reward
- SDK: Llama3 70B Instruct NIM
- SDK: Llama3 8B Instruct NIM
- https://developer.nvidia.com/blog/nvidia-llama-nemotron-ultra-open-model-delivers-groundbreaking-reasoning-accuracy/