



Our latest model, Claude Opus 4.7, is now generally available.
Opus 4.7 is a notable improvement on Opus 4.6 in advanced software engineering, with particular gains on the most difficult tasks. Users report being able to hand off their hardest coding work—the kind that previously needed close supervision—to Opus 4.7 with confidence. Opus 4.7 handles complex, long-running tasks with rigor and consistency, pays precise attention to instructions, and devises ways to verify its own outputs before reporting back.
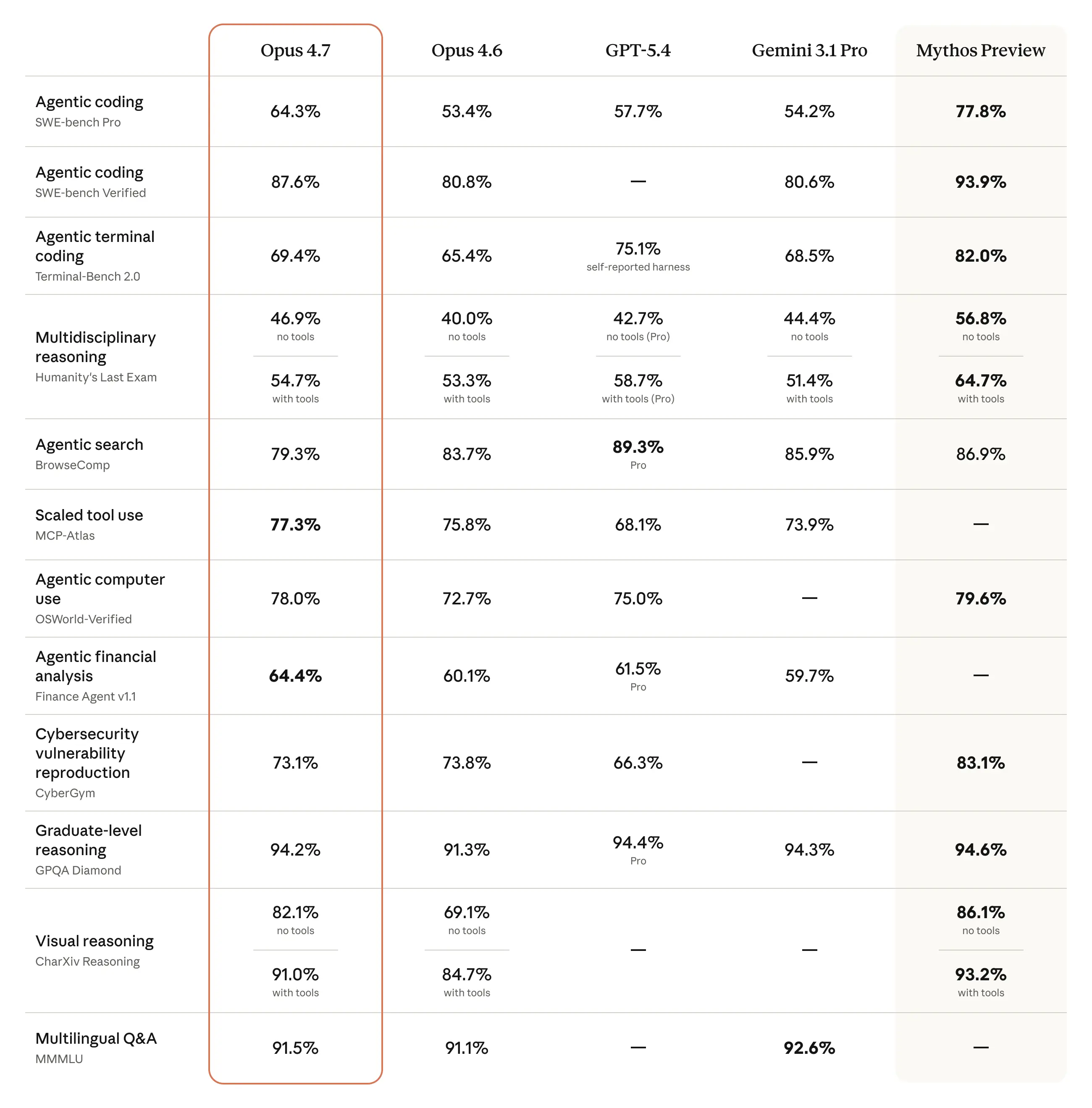
The model also has substantially better vision: it can see images in greater resolution. It’s more tasteful and creative when completing professional tasks, producing higher-quality interfaces, slides, and docs. And—although it is less broadly capable than our most powerful model, Claude Mythos Preview—it shows better results than Opus 4.6 across a range of benchmarks:
Last week we announced Project Glasswing, highlighting the risks—and benefits—of AI models for cybersecurity. We stated that we would keep Claude Mythos Preview’s release limited and test new cyber safeguards on less capable models first. Opus 4.7 is the first such model: its cyber capabilities are not as advanced as those of Mythos Preview (indeed, during its training we experimented with efforts to differentially reduce these capabilities). We are releasing Opus 4.7 with safeguards that automatically detect and block requests that indicate prohibited or high-risk cybersecurity uses. What we learn from the real-world deployment of these safeguards will help us work towards our eventual goal of a broad release of Mythos-class models.
Security professionals who wish to use Opus 4.7 for legitimate cybersecurity purposes (such as vulnerability research, penetration testing, and red-teaming) are invited to join our new Cyber Verification Program.
Opus 4.7 is available today across all Claude products and our API, Amazon Bedrock, Google Cloud’s Vertex AI, and Microsoft Foundry. Pricing remains the same as Opus 4.6: $5 per million input tokens and $25 per million output tokens. Developers can use claude-opus-4-7 via the Claude API.
Testing Claude Opus 4.7
Claude Opus 4.7 has garnered strong feedback from our early-access testers:
Below are some highlights and notes from our early testing of Opus 4.7:
- Instruction following. Opus 4.7 is substantially better at following instructions. Interestingly, this means that prompts written for earlier models can sometimes now produce unexpected results: where previous models interpreted instructions loosely or skipped parts entirely, Opus 4.7 takes the instructions literally. Users should re-tune their prompts and harnesses accordingly.
- Improved multimodal support. Opus 4.7 has better vision for high-resolution images: it can accept images up to 2,576 pixels on the long edge (~3.75 megapixels), more than three times as many as prior Claude models. This opens up a wealth of multimodal uses that depend on fine visual detail: computer-use agents reading dense screenshots, data extractions from complex diagrams, and work that needs pixel-perfect references.1
- Real-world work. As well as its state-of-the-art score on the Finance Agent evaluation (see table above), our internal testing showed Opus 4.7 to be a more effective finance analyst than Opus 4.6, producing rigorous analyses and models, more professional presentations, and tighter integration across tasks. Opus 4.7 is also state-of-the-art on GDPval-AA, a third-party evaluation of economically valuable knowledge work across finance, legal, and other domains.
- Memory. Opus 4.7 is better at using file system-based memory. It remembers important notes across long, multi-session work, and uses them to move on to new tasks that, as a result, need less up-front context.
The charts below display more evaluation results from our pre-release testing, across a range of different domains:
https://www.anthropic.com/news/claude-opus-4-7