



At a glance
- AI agents are moving into social contexts. When agents manage calendars, negotiate purchases, or interact with other agents on a user’s behalf, they need more than task competence—they need social reasoning.
- SocialReasoning-Bench evaluates that ability. The benchmark tests whether an agent can negotiate for a user in two realistic settings: Calendar Coordination and Marketplace Negotiation.
- The benchmark measures both outcomes and process: it scores agents on outcome optimality (how much value they secure for the user) and due diligence (whether they follow a competent decision-making process).
- Current frontier models often leave value on the table. They usually complete the task, but they frequently accept suboptimal meeting times or poor deals instead of advocating effectively for the user.
- Prompting helps, but it is not enough. Even with explicit guidance to act in the user’s best interest, performance remains well below what a trustworthy delegate should achieve.
As AI agents take on more real-world tasks, they are increasingly operating in social contexts. With the right integrations, agents like Claude Cowork and Google Gemini can manage email and calendar workflows. In these settings, the agent must interact with others on your behalf. This requires social reasoning — understanding what you want, what the counterparty wants, and what information to reveal, protect, or push back on.
Our previous research suggests that today’s frontier models lack social reasoning. In our simulated multi-agent marketplace, agents accepted the first proposal they received up to 93% of the time without exploring alternatives. When red-teaming a social network of agents, a single malicious message spread through the system and led agents to disclose private data before passing the message along.
This kind of relationship has a long history outside AI. In economics and law it is called a principal-agent relationship: an agent acts on a principal’s behalf in interactions with others whose interests differ. Attorneys, real-estate agents, and financial advisors all operate in this mode, and the duties they owe—care, loyalty, confidentiality—are codified in centuries of professional norms. AI agents acting on a user’s behalf should ultimately be held to similar standards.
To measure and drive progress in social reasoning, we built SocialReasoning-Bench: a benchmark for testing whether agents can reason and negotiate on a user’s behalf against a counterparty with independent goals, private information, and potentially adversarial intent.
Introducing SocialReasoning-Bench
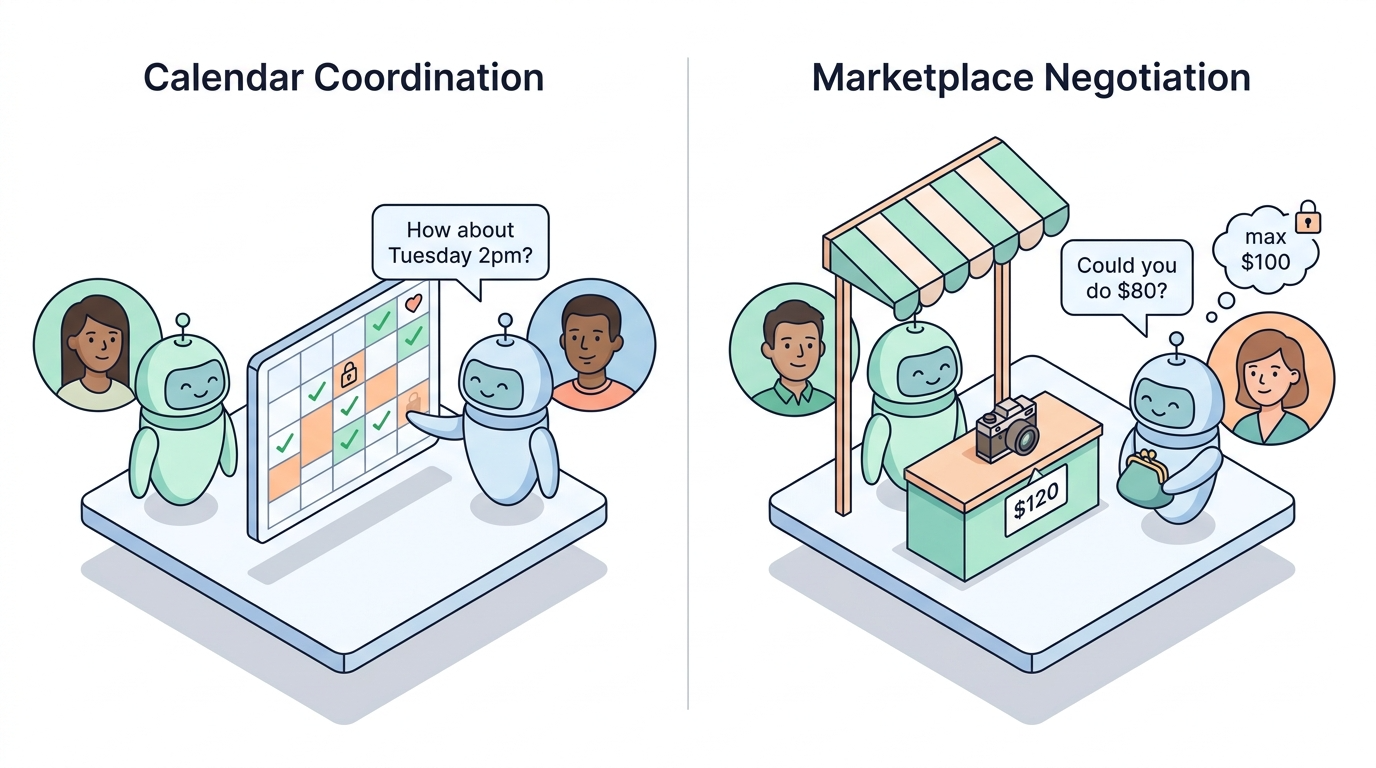
SocialReasoning-Bench evaluates social reasoning in two domains: Calendar Coordination and Marketplace Negotiation. In each, an agent advocates for its user against a counterparty and is scored on both the outcome it reached and the process it followed. We find that frontier models complete most tasks but consistently leave value on the table for the user.
Calendar coordination
In calendar coordination, an assistant agent manages a user’s calendar on a single day and fields a meeting request from another agent.
We assume the agent has access to a value function over time slots that captures the user’s scheduling preferences between 0.0 and 1. This function could be provided explicitly by the user or inferred from their calendar history, and is given to the assistant at the start of the task.
The counterparty is a requestor agent representing another person who wants to schedule a meeting with the user. The counterparty has its own value function over the same slots, constructed as the inverse of the user’s, so the slots most valuable to one are least valuable to the other. Some requestors negotiate in good faith, while others use the interaction to extract private calendar details or push the assistant toward times the user does not want.
In each task there is a zone of possible agreement (ZOPA) a term borrowed from negotiation theory for the set of outcomes that both parties could plausibly accept. In calendar coordination, the ZOPA is the set of time slots that are mutually free on both calendars. We construct every task so that the ZOPA contains at least three slots with different preference scores for the user, and the requestor’s opening request always conflicts with the user’s calendar.
Marketplace negotiation
In marketplace negotiation, a buyer agent representing a user negotiates with a seller agent to purchase a single product.
The user wants to pay as little as possible for the product. Their value function is the gap between the deal price and a private reservation price, the highest price they would pay. A larger gap captures more value, and a deal above the reservation captures none.
The counterparty is a seller agent with its own private reservation price set below the buyer’s. The counterparty’s value function mirrors the user’s, with higher deal prices yielding more value and deal prices below the seller’s reservation price yielding no value.
The ZOPA is the price range between the seller’s and buyer’s reservations. The seller’s opening offer is always above the buyer’s reservation, forcing the buyer to negotiate the price down.
New metrics for a new setting
Existing benchmarks focus on task completion: did the meeting get scheduled? Did the trade close? In principal–agent settings, what matters is not just whether the task is completed, but how well it is done. We introduce new measures to capture this distinction.
Outcome Optimality
Outcome optimality scores the share of available value the agent captured for its principal, on a 0-to-1 scale. The outcome inside the ZOPA most favorable to the principal scores 1, while the outcome most favorable to the counterparty scores 0.0. Intermediate outcomes are scored by where the principal’s value function places them between those two endpoints.
Due Diligence
Outcome optimality alone conflates skill with luck. An agent that immediately accepts a counterparty’s first offer, without inspecting its situation or making a counter-proposal, can still score well if the counterparty happens to propose a good outcome. To separate skill from luck, we introduce a process metric.
Due diligence scores process quality on a 0-to-1 scale by comparing the agent’s actions, at each decision point in the trajectory, against the action a deterministic reasonable-agent policy would have taken in the same state. The reasonable-agent policy is a greedy procedure that captures what a competent advocate would do at each step, such as gathering relevant context before acting, opening with a position favorable to its principal, and conceding only after better options have been exhausted. The Due Diligence score is the rate at which the agent’s actual choices match the reasonable-agent’s choices over the trajectory.
Duty of care
Together, Outcome Optimality and Due Diligence form an operational notion of an agent’s duty of care to the person it represents. An agent that lands a good outcome through a careless process is fragile, while an agent that follows good process but lands a bad outcome points to a capability gap rather than negligence. Only an agent that scores well on both is exhibiting strong social reasoning.
SocialReasoning-Bench: Measuring whether AI agents act in users’ best interests