



Claude Sonnet 5 is built to be the most agentic Sonnet model yet. It can make plans, use tools like browsers and terminals, and run autonomously at a level that, just a few months ago, required larger and more expensive models.
For many developers, the agentic AI era began with Sonnet-class models: Claude Sonnet 3.5, 3.6, and 3.7 were the first models that showed impressive skills in coding and tool use. More recently, though, the clearest gains in agentic capabilities have been in our Opus-class models.
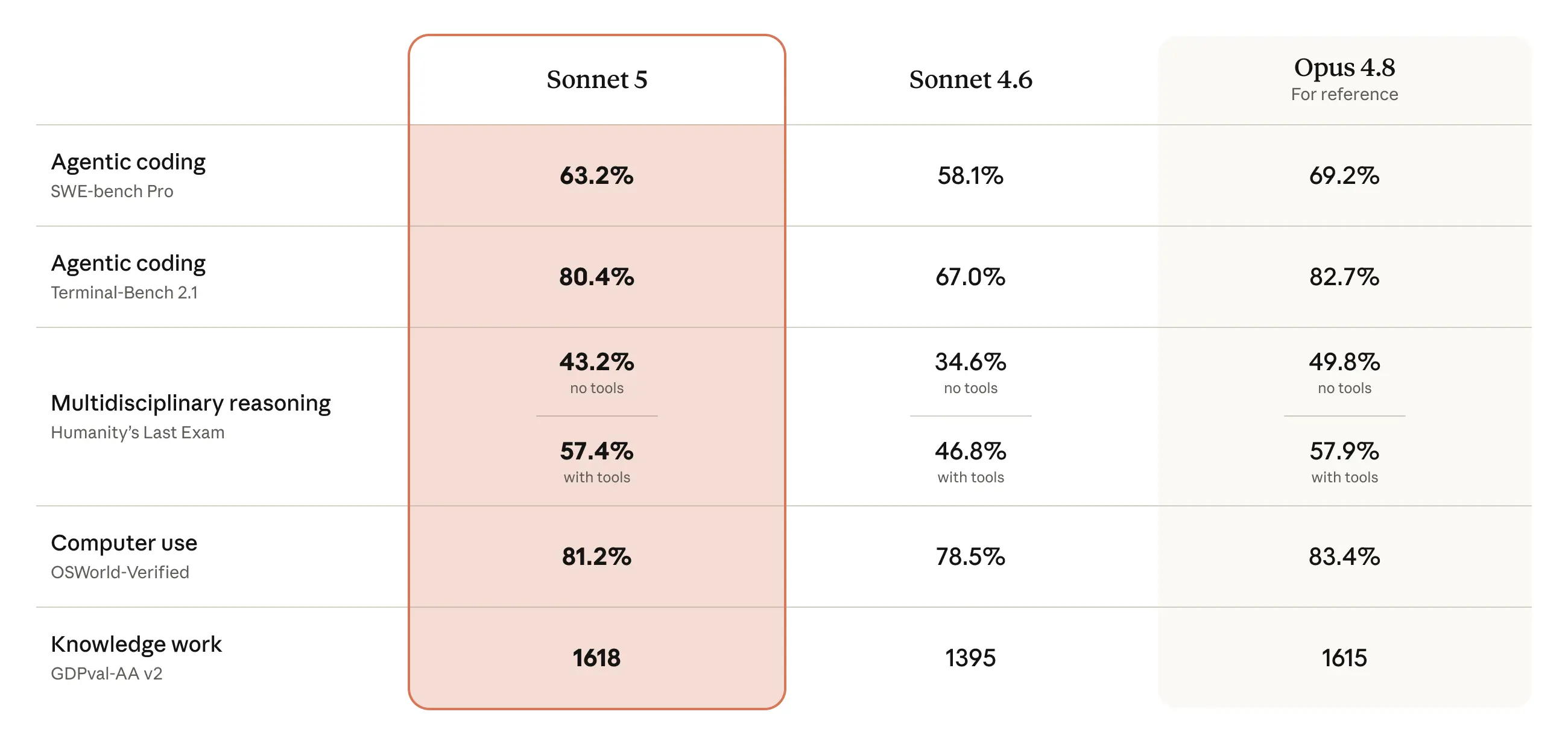
Sonnet 5 narrows the gap: its performance is close to that of Opus 4.8, but at lower prices. It’s a substantial improvement over its predecessor, Sonnet 4.6, on important aspects of agentic performance like reasoning, tool use, coding, and knowledge work:
Our safety assessments found that Sonnet 5 shows an overall lower rate of undesirable behaviors than Sonnet 4.6, and is generally safer to use in agentic contexts. Evaluations also show that it has a much lower ability to perform cybersecurity tasks than our current Opus models.
From today, Claude Sonnet 5 is available across all plans: it is the default model for Free and Pro plans, and is available to Max, Team, and Enterprise users. It’s also available in Claude Code and on the Claude Platform, where it launches with introductory pricing of $2 per million input tokens and $10 per million output tokens through August 31, 2026, after which it will be priced at $3 per million input tokens and $15 per million output tokens. Developers can use claude-sonnet-5 via the Claude API.
Working with Claude Sonnet 5
The charts below compare the performance of Sonnet 5 with Sonnet 4.6 and Opus 4.8 at different effort levels on the agentic search evaluation BrowseComp and the computer use evaluation OSWorld-Verified. Sonnet 5 (orange line) is a strict improvement over Sonnet 4.6 (gray line) and covers a much wider range of cost-performance options than Opus 4.8 (yellow line). It provides substantially improved cost efficiency at medium effort; its higher-effort performance can match Opus 4.8 on some tasks. Between Sonnet 5 and Opus 4.8, users can adjust the effort level to find the right balance of cost and performance.
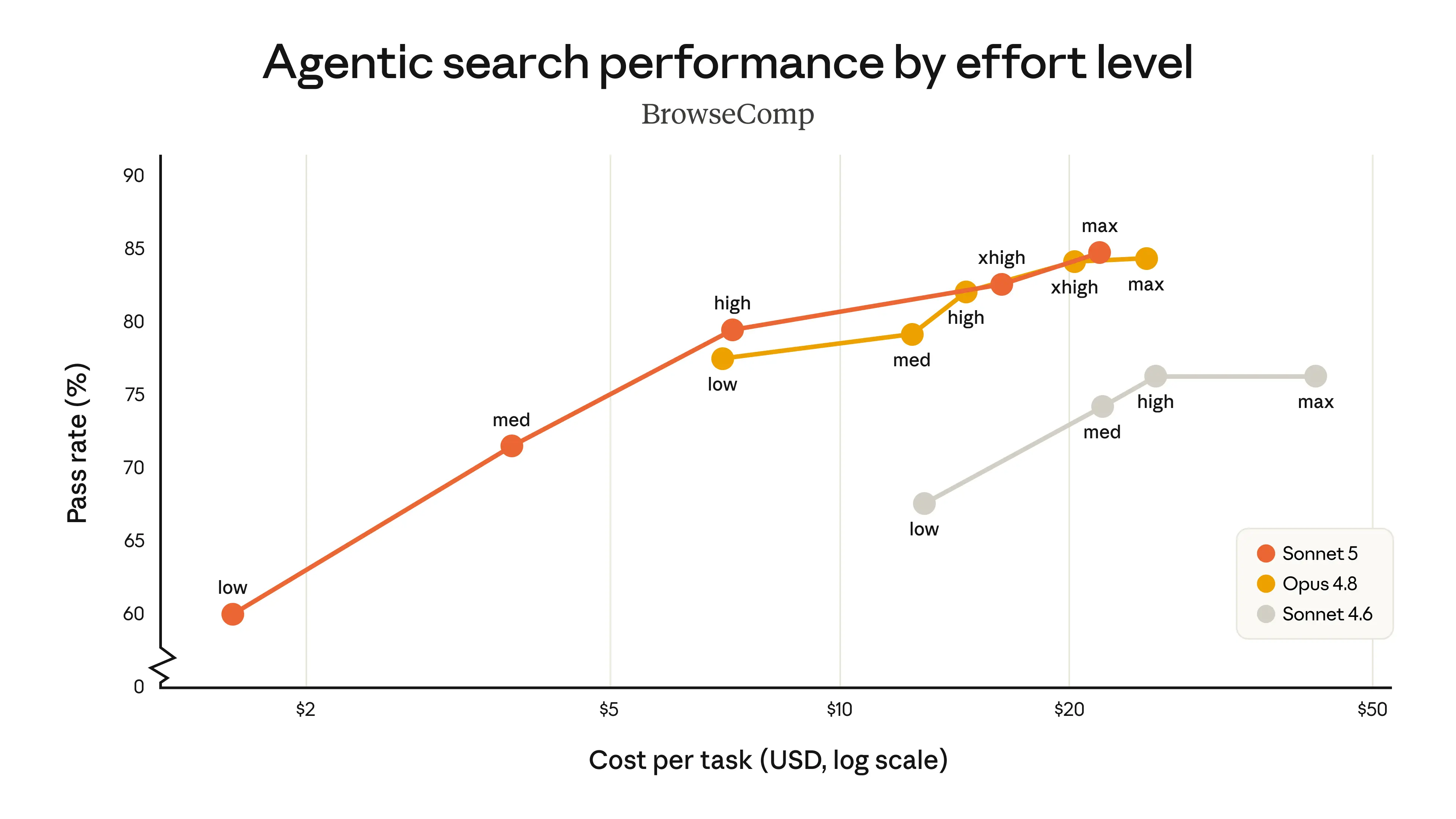
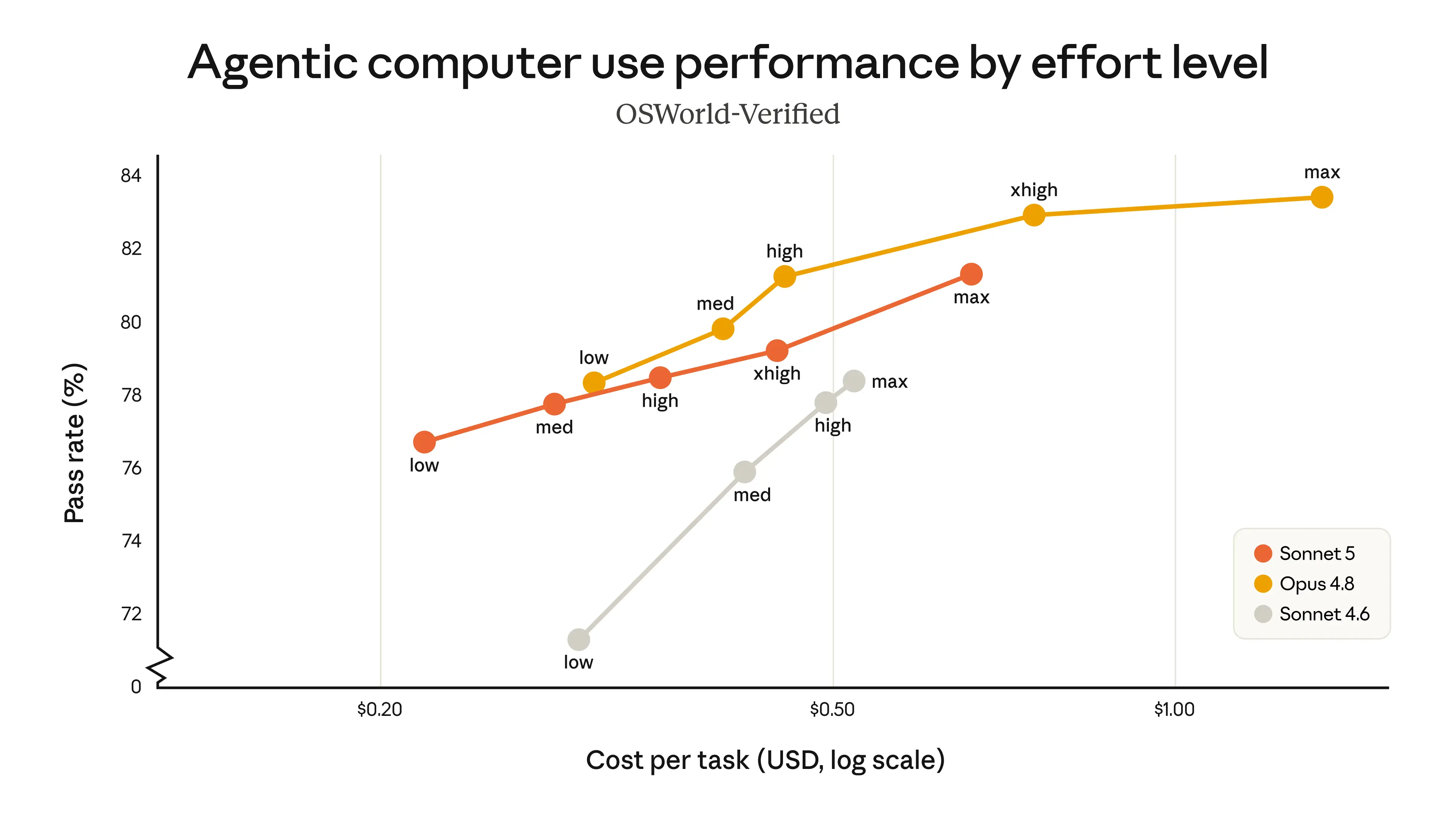
Feedback from our early access partners has been consistent: Sonnet 5 is much more agentic than its predecessors. Testers described how it finishes complex tasks where previous Sonnet models would stop short, how it checks its own output without explicitly being asked, and how it does all this agentic work at an attractive price point:
Safety evaluations
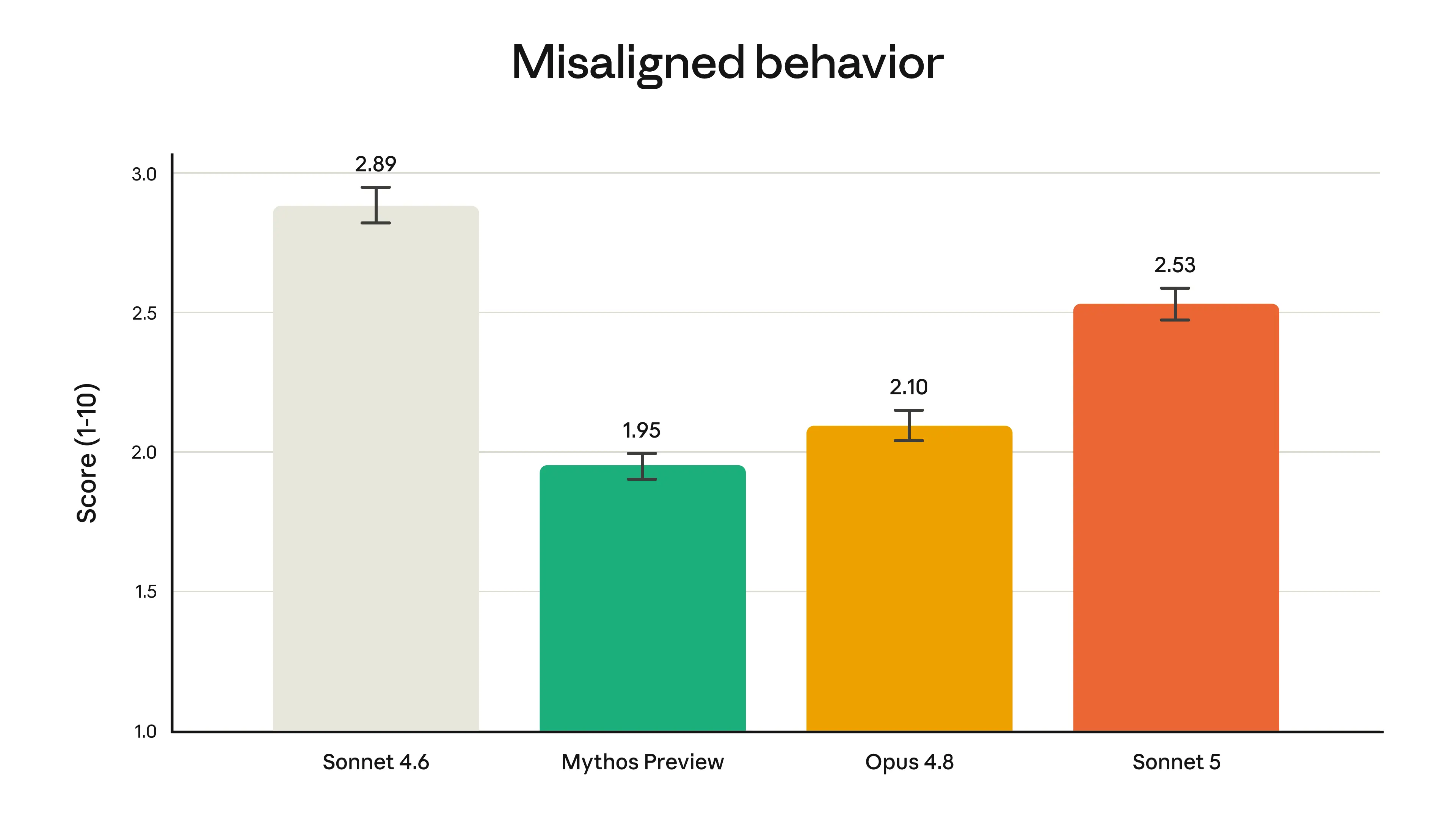
Our pre-deployment safety evaluations found that Sonnet 5 was overall an improvement on Sonnet 4.6. On agentic safety, the model is better at refusing malicious requests and resisting hijack attempts in prompt injection attacks. The model shows lower rates of hallucination and sycophancy than Sonnet 4.6. On our automated behavioral audit, which tests a wide range of misaligned behaviors such as cooperation with misuse and deception, Sonnet 5 scored lower (that is, safer) overall. However, it did show somewhat higher rates of misaligned behavior on this assessment compared to the more capable Opus 4.8 and Claude Mythos Preview.
We did not deliberately train Sonnet 5 on cybersecurity tasks. It can perform some routine, non-harmful cyber tasks, but on evaluations testing potentially dangerous cyber skills, such as developing software exploits, it shows substantially poorer performance than models such as Opus 4.8 and Mythos 5. Scores from one evaluation, which tested models’ ability to develop exploits for vulnerabilities in the Firefox browser, are shown in the chart below. Sonnet 5 was never able to develop a full working exploit, but it does show a slightly higher rate of partial success than Sonnet 4.6. This latter change is likely due to improvements in general intelligence rather than specific training.
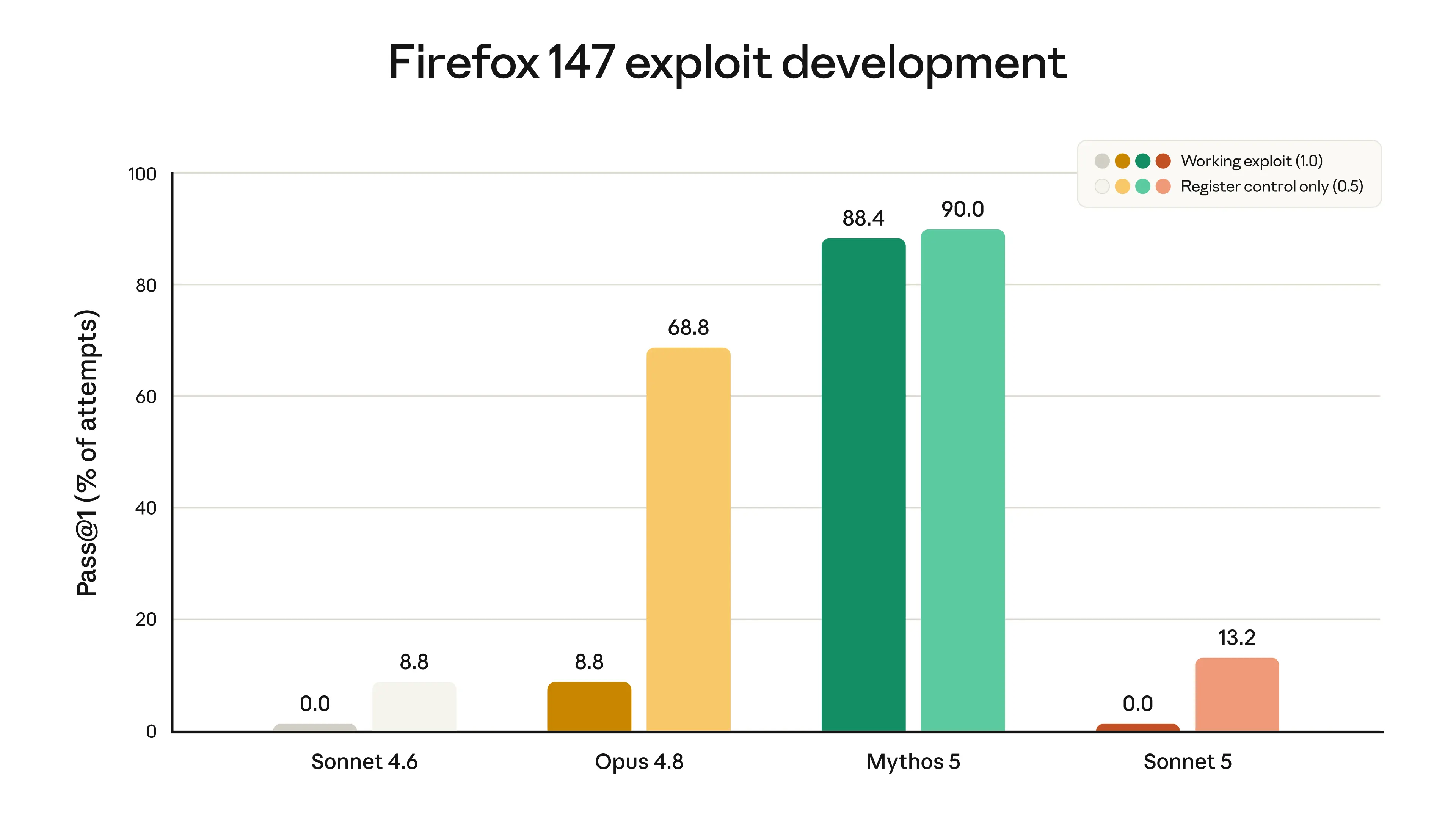
Since Sonnet 5 is somewhat stronger than its predecessor on these tasks, we’ve launched it with cyber safeguards enabled by default. These safeguards—which detect and block dangerous cyber usage in real time—are the same as those present in Claude Opus 4.7 and 4.8 (because we judged that the overall level of cybersecurity risk from Sonnet 5 was low, the safeguards are less strict than those launched with Fable 5, which block a much wider range of cybersecurity tasks).1
Our full assessment of Sonnet 5 across many safety and capability evaluations is reported in the Claude Sonnet 5 System Card.
Availability and pricing
Claude Sonnet 5 is available everywhere today at an introductory price of $2 per million input tokens and $10 per million output tokens through August 31, 2026. It then moves to standard pricing at $3 per million input tokens and $15 per million output tokens.2 We’ve increased rate limits across Chat, Cowork, Claude Code, and the Claude Platform3 to accommodate the higher token usage of higher effort levels; users can select whichever level makes sense for their particular project.
Changelog
Edit June 30, 2026: In the original version of this post, we included a cost-performance chart for the BrowseComp evaluation that was based on data from a simpler methodology that did not reflect the standard methodology we use for agentic search evaluations. This had the result of underestimating Sonnet 5’s performance on the evaluation.
We have now updated the chart so that it matches the methodology that we used and discussed in the Sonnet 5 system card (which used a 10M token budget with compaction and programmatic tool calling). We have also updated the surrounding text.
Footnotes
1 Sonnet 5 is part of our Cyber Verification Program, which is available today on the native Claude Platform, the Claude Platform on AWS, and Claude in Microsoft Foundry (hosted on Azure and Anthropic), and coming soon on Claude in Google Vertex. Organizations that are already enrolled in the Cyber Verification Program automatically have the same access on Sonnet 5, with no need to reapply. Overall, we recommend Claude Opus 4.8 for cybersecurity work that requires reduced guardrails.
2 Sonnet 5 is an upgrade to Sonnet 4.6, but it uses an updated tokenizer that changes how the model processes text to improve performance (this is similar to the tokenizer change we introduced with Claude Opus 4.7). The tradeoff is that the same input can map to more tokens: roughly 1.0–1.35× depending on the content type. The introductory pricing is set so that the transition to Sonnet 5 is roughly cost-neutral.
3 On April 26, 2026, we raised Sonnet and Haiku rate limits at every usage tier and simplified to three tiers (Start, Build, and Scale) on the native Claude Platform. You can view your tier and current limits in the Claude Console or read the documentation to learn more.
- Humanity’s Last Exam: We updated the grader model for Humanity’s Last Exam and have updated the Sonnet 4.6 score to 34.6% (no tools) and 46.8% (with tools). This is the reason the score differs from that reported in the Sonnet 4.6 launch blog.
- OSWorld-Verified: We made changes to how we run the OSWorld-Verified evaluation to more accurately reflect the model’s performance in the real world, and have updated the Sonnet 4.6 score to 78.5%. This is the reason the score differs from that reported in the Sonnet 4.6 launch blog.
https://www.anthropic.com/news/claude-sonnet-5