



Deploying generative AI workloads in production environments where user numbers can fluctuate from hundreds to hundreds of thousands – and where input sequence lengths differ with each request – poses unique challenges. To achieve low latency inference in these environments, multi-GPU setups are a must – irrespective of the GPU generation or its memory capacity. To enhance inference performance in production-grade setups, we’re excited to introduce TensorRT-LLM Multi-shot, a new multi-GPU communication protocol that leverages the NVIDIA NVLink Switch to significantly increase communication speeds by up to 3x. This blog outlines this new feature and how it helps developers and solution architects address the limitations of traditional multi-GPU communication methods.
Challenges with traditional AllReduce algorithms
For low latency inference, multi-GPU is critical, regardless of the memory capacity of a single GPU. However, at low concurrency, the time GPUs spend exchanging data can outweigh the time spent on compute. For optimal performance, an efficient AllReduce operation – a collective operation that combines partial results from each participating GPU – is critical.
Traditional approaches use ring-based algorithms, where the partial values are passed around a ring of GPUs. Each GPU contributes its values and passes the result to its neighbor. This process is repeated 2N-2 times where N is the number of GPUs working together, and by the end of the process, every GPU has the same summed value. A second pass over the ring is required to propagate summed values from the last GPU to the rest.
The Ring approach makes efficient use of available GPU-to-GPU bandwidth per communication step, but as the number of GPUs increases, so does the number of steps. This increases latency, as all GPUs need to stay synchronized at every step of the ring. These synchronization latencies add significant latency overhead and can make it difficult to meet more stringent latency targets.
The Ring AllReduce algorithm is described below:
- Ring Algorithm: GPU-1 → GPU-2 → … → GPU-N → GPU-1 → GPU-2 → … → GPU-(N-1)
- 2N-2 steps, with full tensor send/recv each step
- Latency: 2N-2 communication steps. (N: # of GPUs)
- Traffic: (4N-4)/N tensor bytes of send/recvs
Addressing AllReduce communication challenges with TensorRT-LLM MultiShot
TensorRT-LLM MultiShot is a new algorithm that reduces the O(N) latency of Ring AllReduce by up to 3x leveraging multicast in NVSwitch. Multicast is a hardware acceleration feature in NVSwitch which allows a GPU to send data once and have that data sent simultaneously to all other GPUs, minimizing the number of communication steps to two inter-GPU synchronizations while remaining bandwidth efficient. Without NVSwitch, this would take N times the communication bandwidth.
TensorRT-LLM Multishot separates the AllReduce into a ReduceScatter operation followed by an AllGather operation (for more detailed descriptions of collective operations, see this documentation).
Each GPU is responsible for accumulating only a portion of the result tensor.
The first step (or “shot”) involves each GPU sending the different slices of the tensor to the respective GPU responsible for accumulating that slice of the tensor.
After accumulating locally, each GPU now has the correct sum accumulators for its unique slice of the output.
In the second step (or “shot”), each GPU broadcasts the result slice to all other GPUs using the NVSwitch multicast capability. This minimizes the per GPU bandwidth required as the NVSwitch itself performs data amplification; each GPU sends 1/N the data and receives the full result tensor in one step.
The entire operation only takes two communication steps, regardless of the number GPUs performing tensor parallel inference.
- TensorRT-LLM MultiShot Algorithm: GPU_N sends slices, Compute slice sum, broadcast result in single multicast operation.
- Latency: 2 communication steps (regardless of number of GPUs)
- Traffic: 2 tensor bytes of send/recv (regardless of number of GPUs)
Why this matters
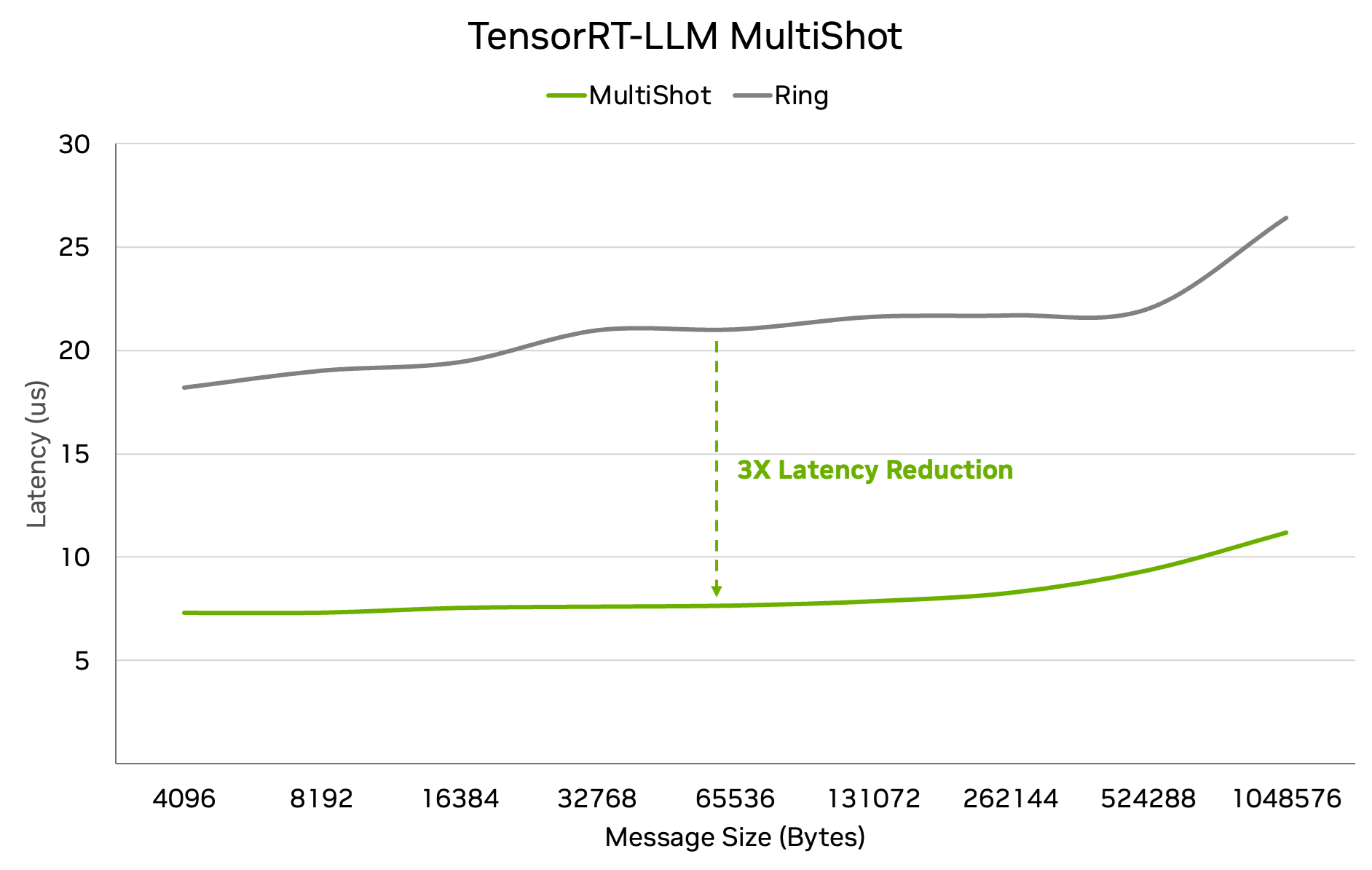
Since this algorithm requires only two communication steps rather than 2N-2 (where N is the number of GPUs), MultiShot can be nearly 3x faster than Ring AllReduce. The benefits of this algorithm are particularly evident with smaller message sizes and high parallelism – the scenario needed when minimum latency is required for a great user experience.
This can be used to either reduce minimum latency, or increase throughput at a given latency. In scenarios with more aggressive latency thresholds, this can lead to super-linear scaling with the number of GPUs.
Achieving optimal inference performance requires careful workload analysis and a deep understanding of performance bottlenecks. By gaining that understanding – both through internal engineering work as well as through close collaboration with external developers and researchers – we can quickly and frequently optimize many aspects of our platform to deliver great performance for users.
As we continue to identify and implement new performance optimizations – some may be extensive, others might be narrower in scope – we will be providing regular updates on these optimizations, providing both technical motivation and quantified benefits.
3x Faster AllReduce with NVSwitch and TensorRT-LLM MultiShot