



AI and scientific computing applications are great examples of distributed computing problems. The problems are too large and the computations too intensive to run on a single machine. These computations are broken down into parallel tasks that are distributed across thousands of compute engines, such as CPUs and GPUs.
To achieve scalable performance, the system relies on dividing workloads like training data, model parameters, or both, across multiple nodes. These nodes must then frequently exchange information, such as gradients of newly-processed model computations during backpropagation in model training, requiring efficient collective communications like all-reduce, broadcast, and gather and scatter operations.
These collective communication patterns ensure the synchronization and convergence of model parameters across the distributed system. The efficiency of these operations is crucial for minimizing communication overhead and maximizing parallel computation, as poorly optimized collective communications can lead to bottlenecks, limiting scalability.
The bottlenecks arise from several factors:
- Latency and bandwidth limitations: Collective operations rely on high-speed data transfers across nodes, which are constrained by the physical network’s latency and bandwidth. As the scale of the system increases, the amount of data to be exchanged grows, and the time taken for communication becomes a dominant factor over computation.
- Synchronization overhead: Many collective operations require synchronization points where all participating nodes must reach the same state before proceeding. If certain nodes are slower, the entire system experiences delays, causing inefficiencies known as stragglers.
- Network contention: As the network becomes more congested with larger numbers of nodes trying to communicate simultaneously, contention for bandwidth and network resources increases, further slowing down collective operations.
- Non-optimal communication patterns: Some collective communication algorithms (e.g., tree-based reductions or ring-based all-reduce) are not always well-optimized for large-scale systems, leading to inefficient use of available resources and increased latency.
Overcoming this bottleneck requires advancements in network technologies (for example, InfiniBand or RDMA) and algorithmic optimizations (for example, hierarchical all-reduce or pipelining techniques) to minimize synchronization delays, reduce contention, and optimize data flow across distributed systems.
Creation of NVIDIA SHARP
The key collective communications enable all compute engines to exchange data between themselves. Managing such communication on a NIC or server requires exchanging massive amounts of data, and is exposed to the variance of latency or collective performance, also known as server jitter.
Migrating the responsibility to manage and execute these collective communications on the switch fabric reduces the amount of transferred data by half and minimizes jitter. NVIDIA Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) is the technology implementing that concept and introduced the concept of in-network computing. It is incorporated in the switch ASIC and designed to accelerate collective communication in distributed computing systems.
Introduced with NVIDIA InfiniBand networks, SHARP offloads collective communication operations—like all-reduce, reduce, and broadcast—from the server’s compute engines to the network switches. By performing reductions (summing, averaging, and so on) directly within the network fabric, SHARP improves these operations and the overall application performance.
Generational advancements with NVIDIA SHARP
The first generation of SHARP was specifically designed for scientific computing applications, with a focus on small-message reduction operations. It was introduced with NVIDIA EDR 100Gb/s switch generation, and was quickly supported by leading Message Passing Interface (MPI) libraries. SHARPv1 small message reduction supported multiple scientific computing applications in parallel.
MVAPICH2 is an open-source implementation of the MPI standard, specifically designed for high-performance computing (HPC) environments. The Ohio State University team responsible for the MVAPICH MPI library has demonstrated the performance achievement of SHARP on the Texas Advanced Computing Center Frontera supercomputer. From 5x higher performance for MPI AllReduce and up to 9x for MPI Barrier collective communications. For more information, see Scalable MPI Collectives using SHARP: Large Scale Performance Evaluation on the TACC Frontera System.
The second generation of SHARP was introduced with the NVIDIA HDR 200Gb/s Quantum InfiniBand switch generation and added support for AI workloads. SHARPv2 includes support for large message reduction operations, supporting a single workload at a time. This version further improved the scalability and flexibility of the technology by supporting more complex data types and aggregation operations.
SHARPv2 performance advantage was demonstrated with NVIDIA MLPerf submission and results in June 2021, demonstrating 17% higher BERT training performance. For more information, see MLPerf v1.0 Training Benchmarks: Insights into a Record-Setting NVIDIA Performance.
Michael Houston, vice president and chief architect of AI systems at NVIDIA, presented the AllReduce performance benefits of SHARPv2, in a UC Berkeley’s Machine Learning Systems course.
The 2x performance benefit of the AllReduce bandwidth translated into 17% higher BERT training performance.
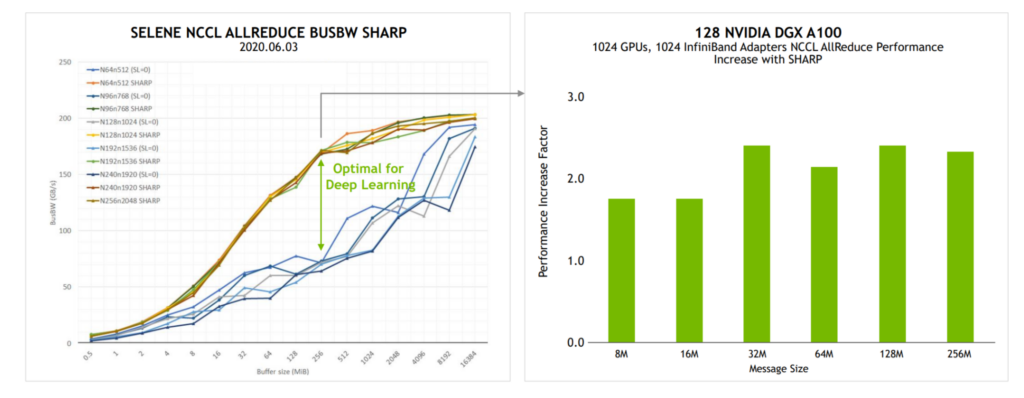
(source: Distributed deep learning, Part II: Scaling Constraints)
Most recently, the third generation of SHARP was introduced with the NVIDIA Quantum-2 NDR 400G InfiniBand platform. SHARPv3 supports multi-tenant in-network computing for AI workloads, meaning that multiple AI workloads are supported in parallel compared to the single workload with SHARPv2.
SHARPv3 performance was presented by Jithin Jose, principal software engineer at Microsoft Azure in the session, Transforming Clouds to Cloud-Native Supercomputing: Best Practices with Microsoft Azure. Jithin covered InfiniBand’s in-network computing technologies at Azure and showcased nearly an order of magnitude performance benefits for AllReduce latency.
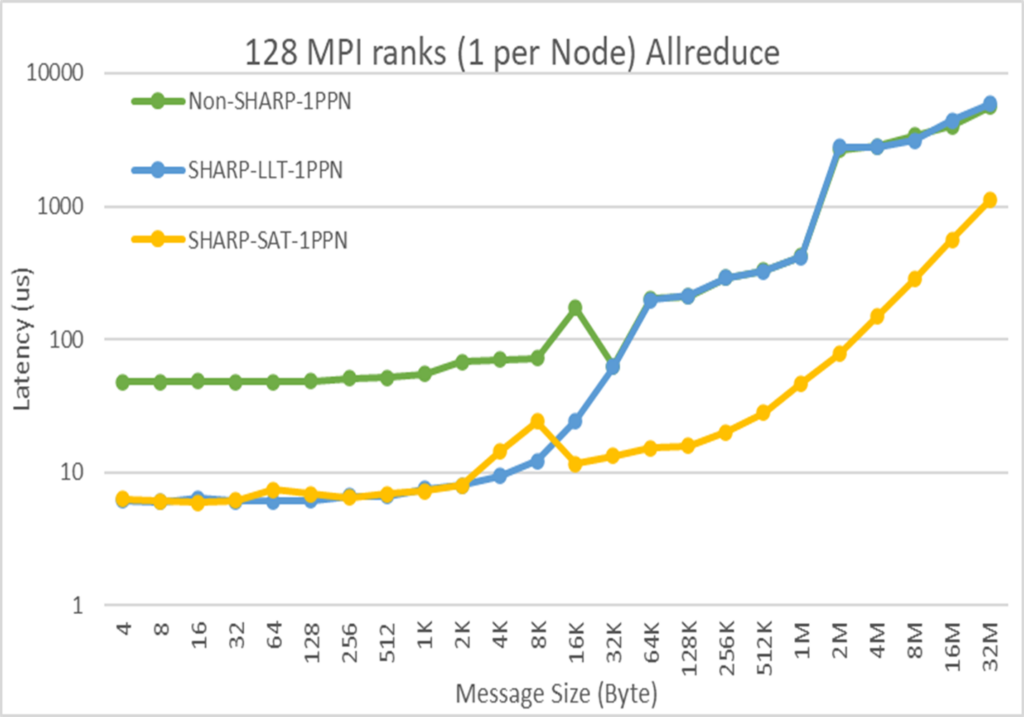
End-to-end AI system optimization
A powerful example of SHARP can be seen with the all-reduce operation. Gradients are summed across multiple GPUs or nodes during model training, and SHARP aggregates the gradients in-network, avoiding the need to send full data sets between GPUs or across nodes. This reduces the communication time, leading to faster iteration times and higher throughput for AI workloads.
Before the era of in-network computing and SHARP, NVIDIA Collective Communication Library (NCCL) communication software would copy all the model weights from the graph, perform an all-reduce operation to sum the weights, and then write the updated weights back to the graph, resulting in multiple data copies.
In 2021, the NCCL team began integrating SHARP, introducing user buffer registration. This enabled NCCL collectives to use pointers directly, eliminating the need to copy data back and forth during the process and improving efficiency.
Today, SHARP is tightly integrated with NCCL, which is widely used in distributed AI training frameworks. NCCL is optimized to take advantage of SHARP by offloading key collective communication operations to the network, significantly improving both the scalability and performance of distributed deep learning workloads.
SHARP technology helps to increase the performance of distributed computing applications. SHARP is being used by HPC supercomputing centers for their scientific computing workloads, and also by AI supercomputers for the AI applications. SHARP is the “secret sauce” that is enabling a competitive advantage. A large service provider uses SHARP to improve its performance across in-house AI workloads from 10–20%.
SHARPv4
SHARPv4 introduces new algorithms to support a larger variety of collective communications that are now used in leading AI training applications. It will be released with the NVIDIA Quantum-X800 XDR InfiniBand switch platforms, delivering the next level of in-network computing.
Summary
For more information, see the following resources:
Related resources
- GTC session: Achieving Higher Performance From Your Data Center and Cloud Application
- GTC session: Full Network Protection for the Largest and Most Complex Networks and Data Centers
- GTC session: Training Deep Learning Models at Scale: How NCCL Enables Best Performance on AI Data Center Networks
- SDK: NCCL
- Webinar: Want to drive innovation and speed up scientific workloads? It starts with the network.
- Webinar: Accelerating Low-Latency Market Data With NVIDIA A100X
Advancing Performance with NVIDIA SHARP In-Network Computing