



In 2024, Google Research drove research breakthroughs and translated them into impact at all scales — computational, human, societal, and global — in an effort to address some of the greatest challenges and scientific questions of our times.
As I reflect on the past year at Google Research, what stands out is the staggering pace of innovation. Never before were we able to advance technologies like AI, foundational ML, algorithms, and quantum computing with the pace, purpose and partnerships that we benefit from today, enabling us to drive innovation and address some of the greatest challenges and scientific questions of our times. We’re building on the rapid rise of machine learning, driving research breakthroughs and translating them into impact at all scales — computational, human, societal, and global. I am proud to share a few highlights from what was an extraordinary year.
Classical and quantum computing: the foundation of innovation
The breakthroughs we made this year in both classical and quantum computing form the basis for a breadth of innovations. Most recently, we took giant strides forward in the field of quantum computing, paving the way towards a useful large-scale quantum computer. Willow, our new quantum chip, delivers state-of-the-art performance: it can perform a benchmark computation in under five minutes, compared to the 10 septillion (1025) years that one of today’s fastest supercomputers would take. Critically, our results published in Nature demonstrated that Willow reduces errors exponentially as we scale up and use more qubits, the units of information in quantum computing. This solves one of the greatest engineering challenges in quantum computing to date, namely that qubits are affected by interactions with the environment, which makes quantum computers prone to errors and limits the number of qubits they can handle. We evaluated the performance of Willow using random circuit sampling, a method we previously reported for assessing the performance of quantum computers. To make quantum computing more reliable and useful, especially at scale, we are also working to identify and correct errors. We introduced AlphaQubit, a neural network–based decoder developed in collaboration with Google DeepMind and published in Nature, that identifies errors with state-of-the-art accuracy. Such innovations bring us closer to a reality where quantum computing can answer previously unsolved scientific challenges from designing nuclear fusion reactors to accelerating drug discovery.
Logical qubits on progressively better processors, with a 2x improvement in physical qubits and increasing size each step up. Red and blue squares correspond to parity checks indicating nearby errors. The processors can reliably execute roughly 50, 103, 106, and 1012 cycles, respectively.
We made strong headway in ML foundations, with extensive work on algorithms, efficiency, data and privacy. We improved ML efficiency through pioneering techniques that reduce the inference times of LLMs, which were implemented across Google products and adopted throughout the industry. Our research on cascades presents a method for leveraging smaller models for “easy” outputs while our novel speculative decoding algorithm computes several tokens in parallel, speeding up the generation of outputs by ~2x–3x without affecting the quality. As a result, LLMs powering conversational products can generate responses significantly faster. This equates to a greatly improved user experience and makes AI more compute- and energy-efficient. We’re building on this work with draft refinement and block verification. We also examined new ways of improving reasoning capabilities of LLMs via pause tokens — increased reasoning power could make smaller models more powerful resulting in significant efficiency gains. We explored the algorithmic efficiency of transformers and designed PolySketchFormer, HyperAttention, and Selective Attention, three novel attention mechanisms, to address computational challenges and bottlenecks in the deployment of language models and to improve model quality.
Our teams have made considerable additional progress, including research on principled deferral algorithms with multiple experts and a general two-stage setting deferral algorithm. Our RL imitation learning algorithm for compiler optimization led to significant savings and reduction of the size of binary files; our research on multi-objective reinforcement learning from human feedback, the Conditional Language Policy framework, provided a principled solution with a key quality-factuality tradeoff and significant compute savings; and work on in-context learning provided a mechanism for sample-efficient learning for sparse retrieval tasks.
Data is another critical building block for ML. To support ML research across the ecosystem, we released and contributed to various datasets. Croissant, for example, is a metadata format designed for the specific needs of ML data, which we designed in collaboration with industry and academia. We developed sensitivity sampling, a data sampling technique for foundation models, and proved that this is an optimal data sampling strategy for classic clustering problems such as k-means. We advanced our research in scalable clustering algorithms, and open-sourced a parallel graph clustering library, providing state-of-the-art results on billion-edge graphs on a single machine. The rapid proliferation of domain-specific machine learning models highlights a key challenge: while these models excel within their respective domains, their performance often varies significantly across diverse applications. To address this, our research developed a principled algorithm by framing the problem as a multiple-source domain adaptation task.
Google Research is deeply committed to privacy research and has made significant contributions to the field. Our work on differentially private model training highlights the importance of rigorous analysis and implementation of privacy-preserving ML algorithms to ensure robust protection of user data. We complemented these analyses with more efficient algorithms for training and new methods for auditing implementations, which we open sourced for the community. In our research on learning from aggregate data, we introduced a novel approach for constructing aggregation datasets, and explored various algorithmic aspects of model learning from aggregated data, which achieved optimistic sample complexity rates in this setting. We also designed new methods for generating differentially private synthetic data — data that is artificial and offers strong privacy protection, while still having the characteristics required for training predictive models.
As we push the boundaries of what can be achieved in computational optimization, there are meaningful implications for the global economy. Take linear programming (LP), a foundational computer science method that informs data-driven decision making and has many applications across fields such as manufacturing and transportation. We introduced PDLP, which requires less memory, is more compatible with modern computational techniques, and significantly scales up LP solving capabilities. It was awarded the prestigious Beale — Orchard-Hays Prize and is now available as part of Google’s open-sourced OR-Tools. We announced our Shipping Network Design API, a great example use-case of PDLP, for optimizing cargo shipping. This enables more environmental and cost-effective solutions to supply chain challenges, with the potential for shipping networks to deliver 13% more containers with 15% fewer vessels. We introduced Times-FM, too, for more accurate time-series forecasting, a widespread type of forecasting used in domains such as retail, manufacturing and finance. This decoder-only foundation model was pre-trained on 100B real world time-points, largely using data from Google Trends and Wikipedia pageviews, and outperformed even powerful deep-learning models that were trained on the target time-series.
We designed PDLP as a software package that can solve linear programming problems efficiently. The core algorithm of PDLP is based on the restarted PDHG, which we have enhanced significantly. Here we show the convergence behaviors of the PDHG and restarted PDHG, where the x-axis is the current solution of the LP, and the y-axis is the current solution of the dual LP.
Applying our research to the popular realm of gaming, our GameNGen model showed that a complex video game can be simulated in real-time and in high-quality with a neural model. And turning to advertising, we partnered with the Ads team to launch ads in AI Overviews on Search to surface more relevant businesses, products, and services within Google’s generative AI experience, while also exploring novel auction design and mechanisms as the experience evolves. We also published a survey of our work in ad auctions with auto bidding.
Advanced approaches make language models more capable and trustworthy
Generative AI is already transforming how we access information, and the trustworthiness of that information is a top priority for users and society as a whole. This year we built on our long legacy of foundational work to advance the quality of AI-generated content. We pioneered state-of-the-art approaches to grounding large language models and reducing hallucinations, for instance by training models to rely on source documents for summarization and combining structured data, such as graphs, with LLMs to improve retrieval augmented generation quality. Our improved models are powering the new “Related sources” and “Double-check” features in Gemini, which enable users to dive deeper into topics and better understand the response to their queries.

Users can click on the chip at the end of a paragraph to display links to related content for fact-seeking prompts in Gemini.
Benchmarks are important for evaluating factual consistency — and we’ve been using them for years in this space. In collaboration with Google DeepMind and Kaggle, we recently shared the FACTS Grounding Leaderboard to provide a platform for more comprehensive benchmarking. The newly launched Gemini 2.0 has achieved a correctness score of 83.6% on the FACTS leaderboard and a <2% hallucination rate on the Vectara leaderboard.
As generative AI becomes multimodal, users also expect generated images and videos to accurately depict real-world scenarios. We introduced Time-Aligned Captions, a framework that can use text descriptions to generate multi-scene videos that are visually consistent from one scene to the next. With our contrastive sequential video diffusion method, it is even possible for scenes that are not adjacent to each other to be visually consistent. This is useful for creating videos with non-linear patterns, such as recipe instructions or do-it-yourself projects. We also trained a unified model to predict rich human feedback, through attention heatmaps, for example, to improve image generation, and we designed a method by which vision language models can articulate misalignments between a text prompt and the generated image. This could deepen our understanding of the causes of misalignment within text–image pairs and help improve generative models.

Examples of implausibility heatmaps. In the Groundtruth heatmap, color represents how many annotators mark the region as implausible. Red/yellow/blue means 3/2/1 annotators mark the regions, respectively. In prediction, color represents the signal strength (probability). The hotter one region is, the more probable the model predicts it as implausible.
Making language models more trustworthy is a long-term endeavor: the increasingly complex nature of ML models necessitates increasingly advanced approaches to ensure their accuracy and helpfulness. That’s why we designed a novel framework to investigate hidden representations in LLMs with LLMs, whereby the model provides natural language explanations about how it represents what it has learned. Going forward, this will allow us to better understand how language models work, fix reasoning errors, and correct hallucinations. We also explored reasoning within transformer-based neural networks. We introduced a representational hierarchy that categorizes graph problems by complexity, characterized transformers’ potential to outperform specialized graph neural networks, and explored how to best represent graphs of connections within a network as text. These studies shed light on the reasoning capabilities of transformers and will enable LLMs to more accurately answer questions about connected information. Alongside accuracy, acknowledging uncertainty in case of multiple possible outputs can help build trust in the same way that a person may say, “I’m not sure, but I think…” Our research evaluates the ability of modern LLMs to convey their own uncertainty and demonstrates the need for better alignment.
As we strive to serve billions of people around the world and make AI accessible for all users, our AI models must embrace different languages, cultures, and value systems. We created multilingual datasets that capture rich and nuanced knowledge about various aspects of global cultures, such as offensive terms, socio-cultural stereotypes, and artifacts. We collaborated with linguists and developed privacy-preserving techniques to identify words that are not officially part of language — new trends like “Wordle” or location names, for example — to improve autocorrection and word prediction features on Gboard. We also pioneered new methods to curate culturally-grounded knowledge from diverse communities, and developed approaches to accelerate the creation of global-scale datasets and drive the next generation of societally-intelligent AI models and agents.
A shift towards personalized healthcare and education
Nowhere does accurate information matter more than in the domains of education and healthcare. In these fields, advances in AI are powering a noteworthy shift towards a more personalized approach. At Google I/O in May, we introduced LearnLM, a family of models fine-tuned for learning that were developed in collaboration with Google DeepMind and product partners. LearnLM is grounded in educational research and makes learning more engaging and personal by dynamically adapting to the learner’s needs and goals. Integrated in our products, this allows students, for example, to “raise your hand” while watching academic videos on YouTube to ask clarifying questions or to ask Gemini to “quiz me” on a topic. We’re working closely with educators to bring these capabilities to the classroom in a safe and helpful way that empowers teachers. To start, we piloted Gemini in Google Classroom, which offers teachers lesson planning features tailored to the target grade level.
Similarly, our fine-tuned models for the medical domain, MedLM and Search for Healthcare on Google Cloud Platform, are helping to democratize access to high-quality, personalized care with generative AI. The models combine Gemini’s multimodal and reasoning abilities with training on de-identified medical data. We demonstrated for the first time how large multimodal models like these can interpret 3D scans or generate state-of-the-art radiology reports. We also introduced an LLM that aims to analyze personal, physiological data from wearable devices and sensors. This Personal Health LLM will be able to provide Fitbit and Pixel users with tailored insights to questions such as “How can I feel more energetic during the day?” Plus, we’re imagining ways that AI systems could be useful conversational partners for clinicians and patients. In partnership with Google DeepMind, we developed Articulate Medical Intelligence Explorer (AMIE), an experimental system optimized for diagnostic reasoning and conversations, which can ask intelligent questions based on a person’s clinical history to help derive a diagnosis, and we explored its potential in subspecialist medical domains, such as breast cancer, where timely diagnosis is crucial.
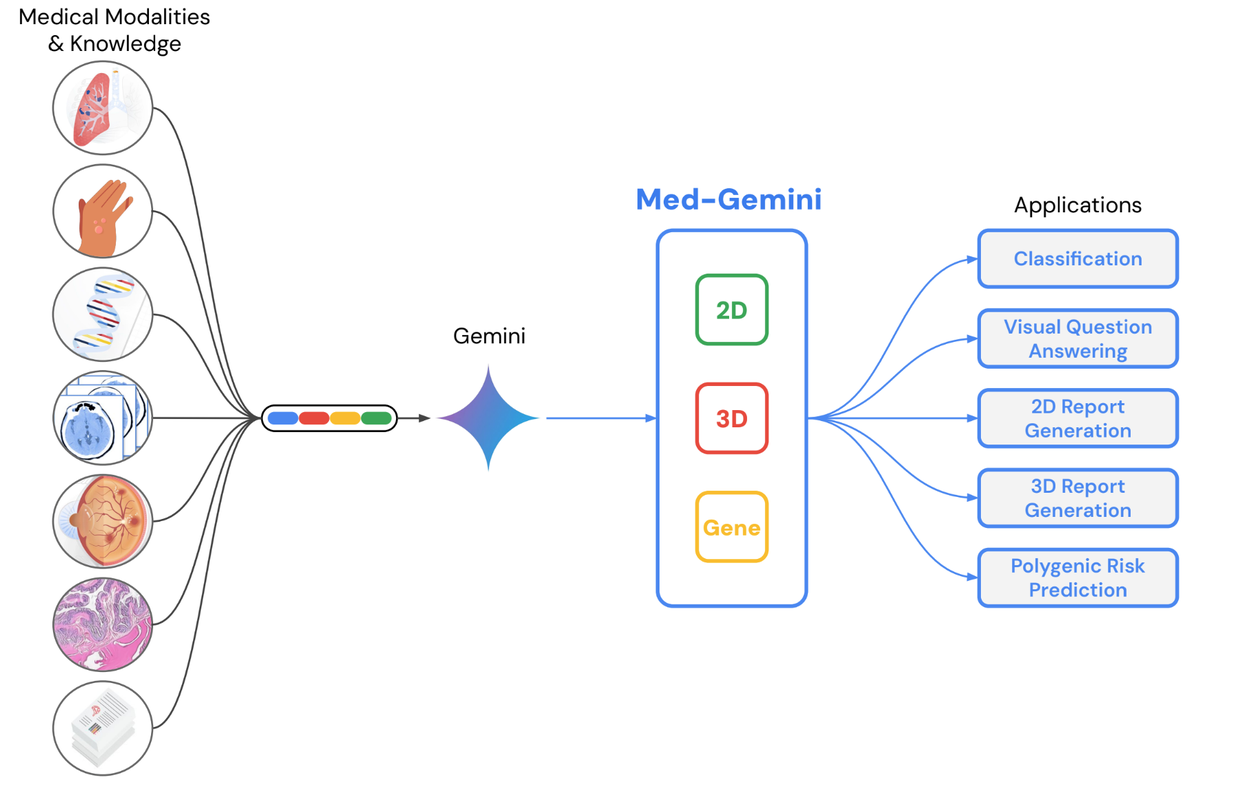
Trained on a range of conventional 2D medical images (chest X-rays, CT slices, pathology slides, etc.) using de-identified medical data with free text labels, Med-Gemini-2D is able to perform a number of tasks, such as classification, visual question answering, and text generation.
We advanced our research into genomics, too, to better understand individuals’ genetic predispositions to illnesses and to diagnose rare diseases. We introduced REGLE, an unsupervised deep learning model that helps researchers use high-dimensional clinical data at scale to discover associations with genetic variants. We also open sourced new DeepVariant models as part of a collaboration on Personalized Pangenome References, which can reduce errors by 30% when analyzing genomes of diverse ancestries.
As we realize the incredible opportunity and benefits of personalized healthcare through the development of ML-based tools, it is imperative to do so in a responsible way. To ensure health equity, we introduced the HEAL framework (Health Equity Assessment of machine Learning performance). This is an evaluation framework to quantitatively assess whether an ML-based health tool performs equitably, in order to inform model development and real-world assessment. The goal is to help reduce disparities in health outcomes for people of different sexes, ethnicities, and socioeconomic backgrounds.
Scaled solutions to scientific and global challenges
As computational techniques and ML models become progressively more advanced and accurate, our researchers are able to address challenges at scale, from GPS accuracy to the pressing issue of climate change.
The ability to process data at an unprecedented scale is helping us to unlock scientific mysteries — and is there a greater mystery than the human brain, arguably the most computationally complex machine in existence? We marked 10 years of connectomics research at Google with a publication in Science released in partnership with Harvard that presented the largest ever AI-assisted reconstruction of human brain tissue at the synaptic level. This can help improve our understanding of how brains work.
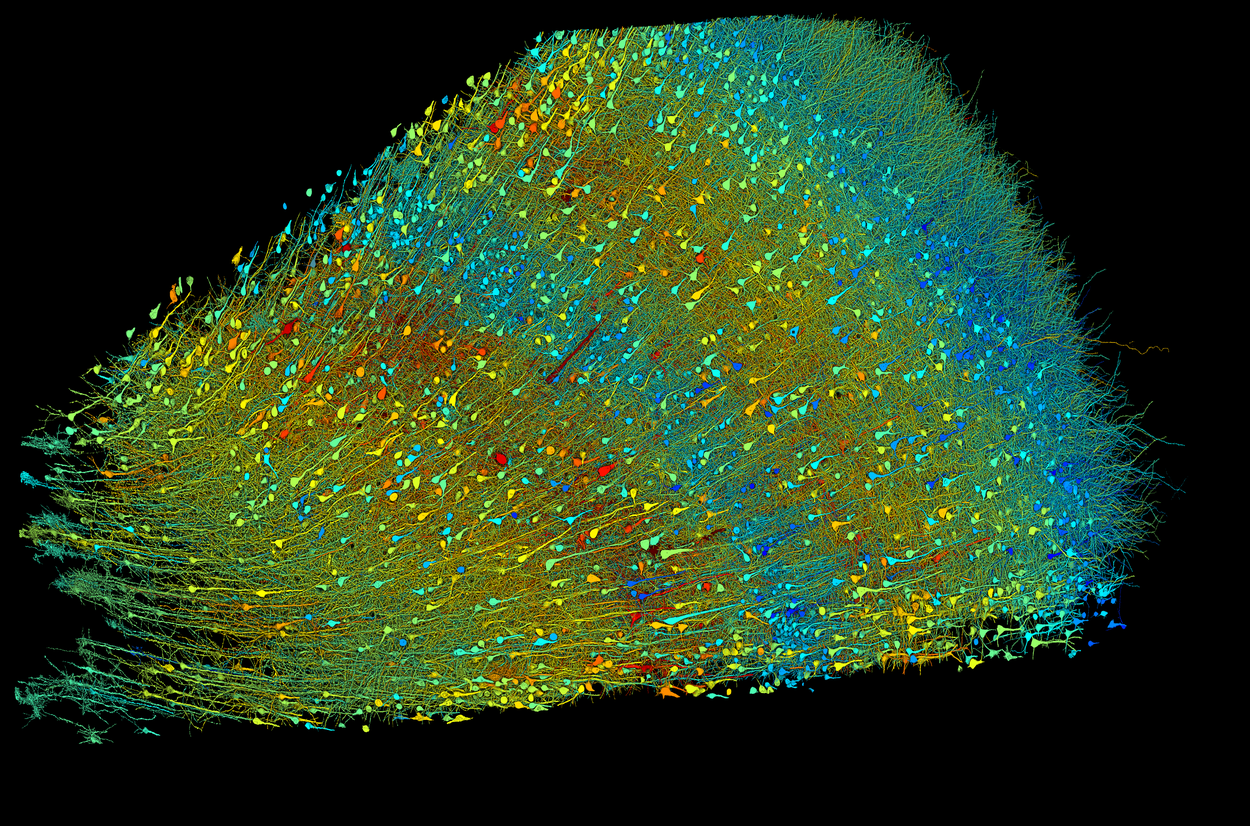
Researchers built a 3D image of nearly every neuron and their connections within a small piece of human brain tissue. This image shows excitatory neurons, which range from 15–30 micrometers across and are shaded according to the size of the neurons’ cell bodies (central core). The sample is approximately 3 mm wide. Credit: Google Research & Lichtman Lab (Harvard University). Renderings by D. Berger (Harvard University).
Our use of aggregated sensor measurements from millions of Android phones to map the ionosphere, a region of the Earth’s upper atmosphere that is ionized by solar radiation, is another example where advances in computing have far-reaching impact. Geomagnetic events in the ionosphere, such as radiation from solar storms, can disrupt critical infrastructure, namely satellite communications and navigation systems. The mapping, published in Nature, will enable us to improve the accuracy of GPS location by several meters and provides scientists with an unprecedented level of detail about the ionosphere in regions that have few monitoring stations. We also introduced NeuralGCM in Nature, a model that can accurately simulate the earth’s atmosphere more quickly than state-of-the-art physics models. It was developed in partnership with the European Centre for Medium-Range Weather Forecasts and combines traditional physics-based modeling with ML. We made the source code available on GitHub in the hope that other researchers can improve model functionality, and going forward it will help scientists understand and predict how our climate is changing over time. SEEDS is another innovation that opens up new opportunities for weather and climate science: it is a generative AI model that can efficiently generate weather forecasts at scale at a fraction of the cost of traditional physics-based forecasting models.
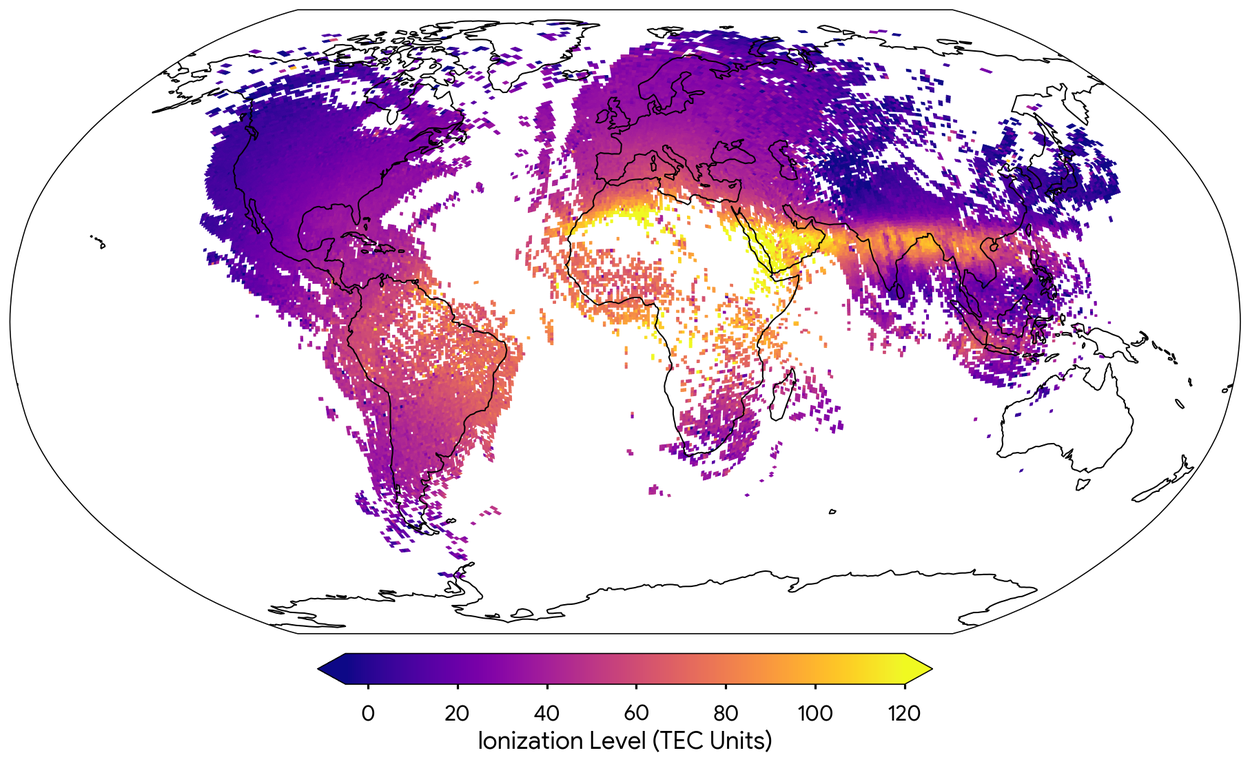
A worldwide map of atmospheric ionization made from ten minutes of phone measurements on October 12, 2023 at 2:00 p.m. UTC. The color gradient shows the amount of ionization, from purple (low ion density) to yellow (high ion density). Data was captured in places where we had sufficient measurements: the daytime side of the earth and areas with greater population density.
NeuralGCM simulated patterns of specific humidity over a 14-day period from December 26, 2019 through January 8, 2020. Higher values of specific humidity are shown in lighter colors.
Reliable, timely information is critical for empowering communities and governments to take action to minimize damage from natural disasters, such as floods and wildfires, phenomena that are becoming more frequent and destructive as global temperatures rise. We developed AI-based hydrology models, published in Nature earlier this year, capable of forecasting riverine floods around the world even in data-scarce regions like Africa. We further improved the model so it now provides coverage for over 700 million people living in at-risk areas in 100 countries, with a 7-day lead time before floods occur, surpassing state-of-the-art models. All information is publicly available on Flood Hub, and we offer researchers and expert users in disaster management domains the opportunity to sign-up for API access for more data. To help people stay safe when wildfires occur, we expanded our wildfire boundary tracker to cover 22 countries. It uses AI and satellite imagery, and makes critical information available in Search, Maps, and through location-based push notifications. We released our Firebench dataset to advance research in this field, making it available on the Google Cloud Platform. This high-resolution, synthetic dataset enables researchers to simulate and investigate wildfire spread behavior and supports the development of ML solutions by capturing the dependencies between relevant variables. We also partnered with the Moore Foundation and Muon Space to develop FireSat, a purpose-built constellation of satellites aiming to detect wildfires anywhere around the world within twenty minutes and to allow scientists and ML experts to study fire propagation.

We are developing FireSat, the first satellite constellation to focus on the early detection of wildfires in high resolution imagery.
Underpinning much of our climate research, and enabling us to address a spectrum of other pressing global challenges, is the development of foundational models. For example, we introduced a population dynamics foundation model and dataset which can be easily adapted to solve a wide array of geospatial problems spanning public health, socioeconomic, and environmental tasks. At the heart of the model is a graph neural network. It incorporates aggregated human-centric data, environmental data, and local characteristics to enable a more nuanced understanding of population dynamics around the world.
Responsible progress through partnerships
At Google Research, we highly value collaboration and partnerships, and we engage with the broader research ecosystem through publications, the release of datasets and open-source models, partnerships with universities and organizations around the world, and participation in research conferences, such as the recent NeurIPS.
This goes hand-in-hand with having a global team who collaborate with partners on the ground and pursue research that addresses the needs of their communities. Our teams in Africa, for example, are leading our research on food security in partnership with the World Food Programme and with funding from Google.org, and we partner with the UN and GiveDirectly to make our flood forecasting technology and disaster response helpful to local communities. Our health team developed an AI tool for screening diabetic patients to help prevent blindness along with research partners in India and Thailand, and licensed the model to healthcare providers with the aim to deliver 6 million screenings over the next 10 years, at no cost to patients. This team is also working across continents to evaluate the impact of an AI assistant for lung cancer screening on clinical workflows in Japan and the US.
Through collaboration, we are able to both advance cutting-edge research and responsibly apply our solutions in the real-world, in line with our core responsible AI principles to ensure that our research upholds the highest standards of scientific excellence and is socially beneficial.
I want to take this opportunity to thank everyone at Google Research and our many partners for the remarkable progress and impact this year — the above is only a snapshot of what we’ve achieved together. As we continue to advance technologies like AI, Quantum, Algorithms, and foundational ML, I’m optimistic about the positive impact we can have on billions of people and the world.
With thanks to everyone in Google Research, and many collaborators, who have contributed to this blog and the work represented here.
https://research.google/blog/google-research-2024-breakthroughs-for-impact-at-every-scale/