


As models grow larger and are trained on more data, they become more capable, making them more useful. To train these models quickly, more performance, delivered at data center scale, is required. The NVIDIA Blackwell platform, launched at GTC 2024 and now in full production, integrates seven types of chips: GPU, CPU, DPU, NVLink Switch chip, InfiniBand Switch, and Ethernet Switch. The Blackwell platform delivers a large leap in per-GPU performance and is set to enable the creation of even larger-scale AI clusters, fueling the development of next-generation LLMs.
In the latest round of MLPerf Training – a suite of AI training benchmarks – NVIDIA made its first submissions using the Blackwell platform in the preview category of the benchmark. These results demonstrated large gains per-accelerator compared to Hopper-based submissions on every MLPerf Training benchmark. Highlights include per-GPU performance boosts of 2x for GPT-3 pre-training and 2.2x for Llama 2 70B low-rank adaptation (LoRA) fine-tuning. NVIDIA also submitted results running on Blackwell on every MLPerf Training benchmark this round, delivering solid gains compared to Hopper across the board.
Each system submitted incorporates eight Blackwell GPUs operating at a thermal design power (TDP) of 1,000W, connected using fifth-generation NVLink and the latest NVLink Switch. The nodes are connected using NVIDIA ConnectX-7 SuperNICs and NVIDIA Quantum-2 InfiniBand switches. Looking ahead, GB200 NVL72 – which features more compute, expanded NVLink domain, higher memory bandwidth and capacity, and tight integration with the NVIDIA Grace CPU – is expected to deliver even more performance per GPU compared to the HGX B200, and enable efficient scaling with the ConnectX-8 SuperNIC and new Quantum-X800 switches.
In this post, we take a closer look at these stellar results.
Enhancing the software stack for Blackwell
With each new platform generation, NVIDIA extensively co-designs hardware and software to allow developers to achieve high delivered workload performance. The Blackwell GPU architecture delivers large leaps in Tensor Core compute throughput and memory bandwidth. Many aspects of the NVIDIA software stack were enhanced to take advantage of the significantly improved capabilities of Blackwell in this round of MLPerf Training, including:
- Optimized GEMMs, Convolutions and Multi-head Attention: New kernels were developed to make efficient use of the faster and more efficient Tensor Cores in the Blackwell GPU architecture.
- More Efficient Compute and Communication Overlap: Architecture and software enhancements allow for better use of available GPU resources during multi-GPU execution.
- Improved Memory Bandwidth Utilization: New software was developed as part of cuDNN library that makes use of the Tensor Memory Accelerator (TMA) capability, first introduced in the Hopper architecture, improving HBM bandwidth utilization for several operations, including normalizations.
- More Performant Parallel Mapping: Blackwell GPUs introduce a larger HBM capacity, which allows for parallel mappings of language models that use hardware resources more efficiently
Additionally, to improve performance on Hopper, we enhanced cuBLAS with support for more flexible tiling options and improved data locality. Optimized Blackwell multi-head attention kernels and convolution kernels in cuDNN have leveraged cuDNN Runtime Fusion Engines. The NVIDIA Transformer Engine library has been instrumental to achieving optimized performance for language models through a combination of optimizations explained above.
The combination of the many innovations in the Blackwell architecture, the optimizations described above, as well as many more enhancements to the software stack not described here, contributed to outstanding performance gains across the board.
Blackwell delivers a giant leap for LLM pre-training
The MLPerf Training suite includes an LLM pre-training benchmark based on the GPT-3 model developed by OpenAI. This test is intended to represent state-of-the-art foundation model training performance. On a per-GPU basis, Blackwell results this round delivered twice the performance of Hopper in its fourth submission. And, compared to results gathered on HGX A100 (not verified by MLCommons) – based on the NVIDIA Ampere architecture – performance per GPU has increased by about 12x.
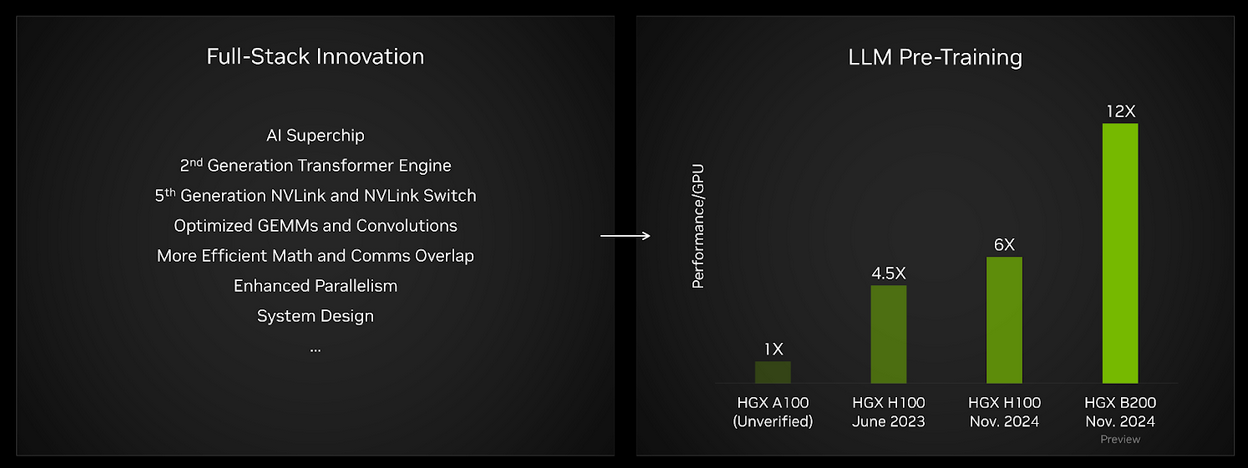
MLPerf Training, Closed. HGX H100 June 2023, HGX H100 November 2024, and HGX B200 results verified by MLCommons Association. HGX A100 results not verified by MLCommons. Verified results obtained from entries 3.0-2069 (512 H100 GPU), 4.1-0060 (512 H100 GPUs), and 4.1-0082 (64 Blackwell GPUs) and normalized per GPU. Performance/GPU is not the primary metric of MLPerf Training. The MLPerf name and logo are registered and unregistered trademarks of MLCommons association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
Additionally, as a result of the larger, higher-bandwidth HBM3e memory per Blackwell GPU in the HGX B200, it was possible to run the GPT-3 benchmark using just 64 GPUs without compromising per-GPU performance. Meanwhile, to achieve optimal per-GPU performance using HGX H100, a submission scale of 256 GPUs (32 HGX H100 servers) was required. The combination of much higher per-GPU compute throughput, and much larger and faster high-bandwidth memory, allows the GPT-3 175B benchmark to run on fewer GPUs while achieving excellent performance per GPU.
Blackwell accelerates LLM fine-tuning
With the advent of large and capable community LLMs, such as the Llama family of models by Meta, enterprises have access to a wealth of capable pre-trained models. These models can be customized to improve performance on specific tasks through fine-tuning. MLPerf Training recently added an LLM fine-tuning benchmark, which applies low-rank adaptation (LoRA) – a type of parameter-efficient fine tuning (PEFT) – to the Llama 2 70B model.

Performance comparisons on Llama 2 70B LoRA fine-tuning based on comparison of DGX B200 8-GPU submissions using Blackwell GPUs in entry 4.1-0080 (preview category) with 8-GPU HGX H100 submission in entry 4.1-0050 (available category). GPT-3 175B comparison compares normalized per-GPU performance of 256 H100 GPU submission in entry 4.1-0057 (available category) with normalized per-GPU 64 Blackwell GPU submission in 4.1-0082 (preview category). Results verified by MLCommons Association. The MLPerf name and logo are registered and unregistered trademarks of MLCommons association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
On the LLM fine-tuning benchmark, a single HGX B200 server delivers 2.2X more performance compared to an HGX H100 server. This means that organizations can more quickly customize LLMs with Blackwell compared to Hopper, speeding time to deployment and, ultimately, value.
Blackwell submissions on every benchmark
NVIDIA submitted results using Blackwell on every benchmark, delivering significant performance gains across the board.
| Benchmark | Blackwell Per-GPU Uplift vs. Latest H100 Performance |
| LLM LoRA Fine-Tuning | 2.2x |
| LLM Pre-Training | 2.0x |
| Graph Neural Network | 2.0x |
| Text-to-Image | 1.7x |
| Recommender | 1.6x |
| Object Detection | 1.6x |
| Natural Language Processing | 1.4x |
MLPerf Training v4.1, Closed. Results retrieved on November 13, 2024, from the following entries: 4.1-0048, 4.1-0049, 4.1-0050, 4.1-0051, 4.1-0052, 4.1-0078, 4.1-0079, 4.1-0080, 4.1-0081, 4.1-0082. Speedups calculated by comparing normalized performance per GPU. Per-GPU performance is not a primary metric of MLPerf Training. The MLPerf name and logo are registered and unregistered trademarks of MLCommons association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
Hopper continues to deliver great performance
The NVIDIA Hopper architecture continued to deliver the highest performance among available solutions in MLPerf Training v4.1, both on a normalized per-accelerator basis as well as at scale. For instance, on the GPT-3 175B benchmark, Hopper performance on a per-accelerator basis has increased by 1.3X since the first Hopper submission on the benchmark in MLPerf Training v3.0, for which results were published in June of 2023.
In addition to improving better delivered performance per GPU, NVIDIA has dramatically improved scaling efficiency, enabling the GPT-3 175B submission using 11,616 H100 GPUs, which continues to hold benchmark records for both overall performance as well as submission scale.
NVIDIA also submitted results using the HGX H200 platform. The NVIDIA H200 Tensor Core GPU is built using the same Hopper architecture as the NVIDIA H100 Tensor Core GPU, equipping it with HBM3e memory, providing 1.8X more memory capacity and 1.4X more memory bandwidth. On the Llama 2 70B low-rank adaptation (LoRA) benchmark, the NVIDIA 8-GPU submission using the H200 delivered about 16% better performance compared to the H100.
Key takeaways
The NVIDIA Blackwell platform represents a significant performance leap compared to the Hopper platform, particularly for LLM pre-training and LLM fine-tuning, as demonstrated in these MLPerf Training results. And, Hopper continues to deliver great performance both per-GPU and at scale, with software optimization further enhancing performance since its introduction. In future MLPerf Training rounds, we look forward to submitting Blackwell at an even greater scale, as well as submitting results using the rack-scale GB200 NVL72 system.
NVIDIA Blackwell Doubles LLM Training Performance in MLPerf Training v4.1