



The latest wave of open source large language models (LLMs), like DeepSeek R1, Llama 4, and Qwen3, have embraced Mixture of Experts (MoE) architectures. Unlike traditional dense models, MoEs activate only a subset of specialized parameters—known as experts—during inference. This selective activation reduces computational overhead, leading to faster inference times and lower deployment costs.
When combined with NVIDIA Dynamo’s inference optimization techniques (such as disaggregated serving) and the large domain size of NVIDIA GB200 NVL72’s scale-up architecture, MoE models benefit from a compounding effect that unlocks new levels of inference efficiencies. This synergy can significantly increase margins for AI factories, enabling them to serve more user requests per GPU without sacrificing user experience.
This blog draws on findings from our recent research, where we evaluated hundreds of thousands of design points across diverse hardware configurations using a high-fidelity data-center scale GPU performance simulator. We analyzed how disaggregation and wide model parallelism affect MoE throughput.
Boosting MoE model performance with disaggregated serving
Since the introduction of the BERT model in 2018 by Google Researchers, model weights have grown by over 1,000x and the throughput and interactivity expectations for generative inference have only increased. Hence, it is now common practice to shard models across multiple GPUs using model parallelism techniques like Tensor Parallelism (TP), Pipeline Parallelism (PP), and Data Parallelism (DP).
Traditional LLM deployments often co-locate the prefill and decode phases of inference on a single GPU or node. However, the inherently token-parallel prefill phase has distinct resource requirements from the autoregressive decode phase. In typical serving scenarios, the service level agreements(SLAs) applicable to the phases are also distinct, with Time to First Token (TTFT) requirements applying to prefill and Inter-Token Latency (ITL) requirements guiding decode deployment choices. As a result, each phase benefits from different model parallelism choices. Co-locating these phases leads to inefficient resource utilization, especially for long input sequences.

Disaggregated serving separates these phases across different GPUs or GPU nodes, allowing for independent optimization. This separation enables the application of various model parallelism strategies, and the assignment of different numbers of GPU devices to meet the particular needs of each phase, enhancing overall efficiency.
MoE models divide the model into specialized experts. Instead of activating the entire model for every token, a gating mechanism dynamically selects a small subset of these experts to process each token. Each incoming token is routed to the selected experts, which then perform computations and exchange results via all-to-all GPU communication.
The unique architecture of MoEs allows for the introduction of a new dimension of model parallelism known as Expert Parallelism (EP). In EP, model experts are distributed across GPUs, enabling richer model parallel mappings and improving resource utilization.
Adding EP to the mix of existing model parallelism techniques—such as TP, PP, and DP—dramatically expands the model parallel search space when serving MoE models in disaggregated serving, allowing for more tailored parallelism strategies for prefill and decode.
In MoE models, the decode phase performs best with a wide EP setup, where each GPU hosts only a small number of experts. This approach distributes compute more evenly across GPUs, which helps reduce processing latency. At the same time, fewer experts per GPU free up GPU memory for KV Cache, allowing each GPU to handle more requests per batch to increase overall throughput.
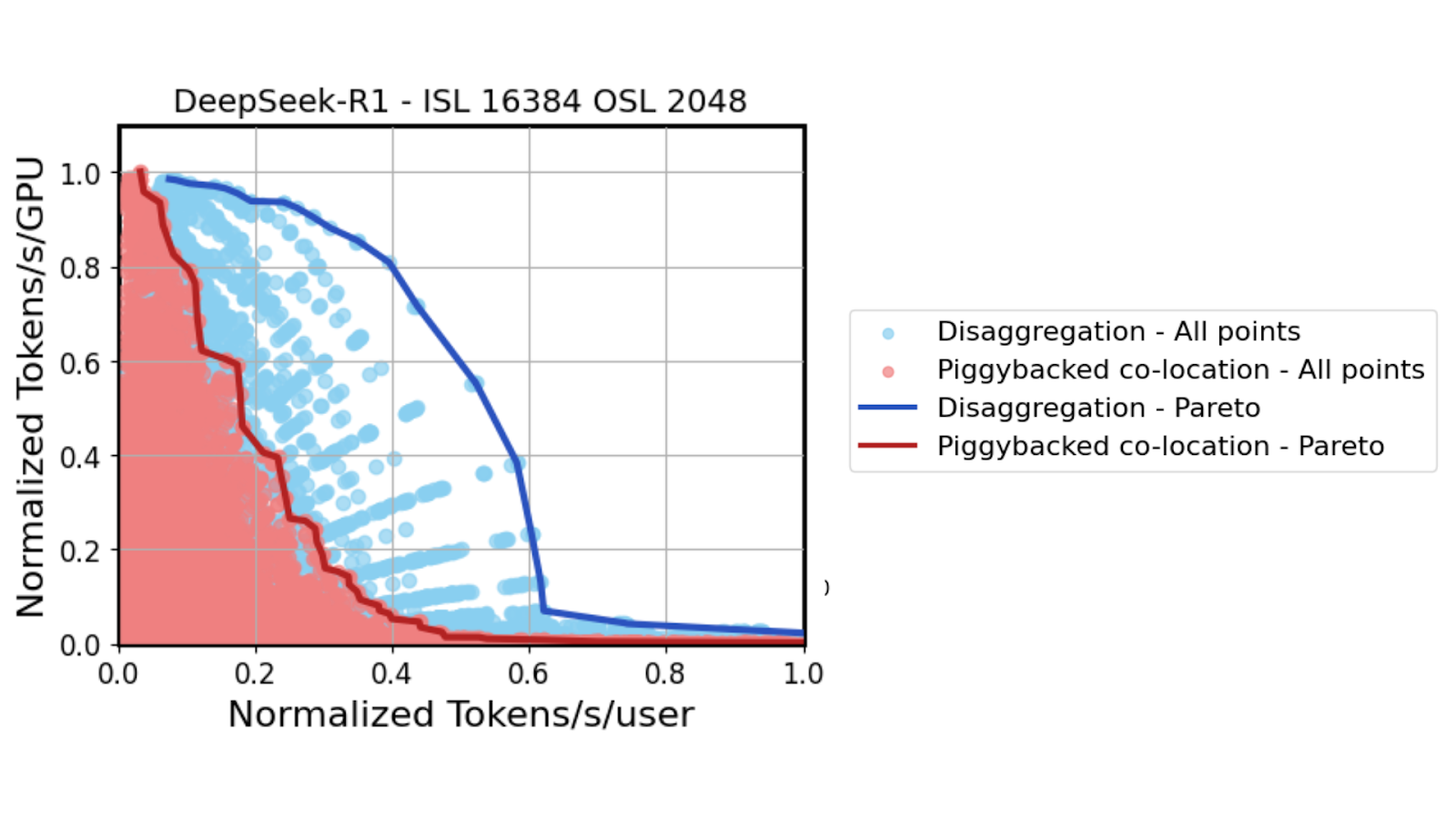
When testing the DeepSeek R1 model using a high fidelity data-center scale GPU simulator across hundreds of thousands of potential model parallel configurations, a 6x throughput performance gain can be achieved in the medium latency regime (midpoint on x-axis).
NVIDIA Dynamo powers disaggregated serving for MoE models
NVIDIA Dynamo is a distributed inference serving framework designed for deploying models at data-center scale. It simplifies and automates the complexities introduced by disaggregated serving architectures. This includes managing the rapid transfer of the KV cache between prefill and decode GPUs, intelligently routing incoming requests to the appropriate decode GPUs that hold the relevant KV cache for efficient computation. Dynamo also enables scaling the entire disaggregated setup to tens of thousands of GPUs using NVIDIA Dynamo Planner and Kubernetes when user demand exceeds allocated capacity.
One key challenge in a disaggregated setup is the need for request rate matching between prefill and decode GPUs. Dynamic rate matching ensures resources are allocated based on load across the prefill and decode phases. It prevents decode GPUs from sitting idle while waiting for KV cache from prefill (i.e., prefill dominated scenarios), and avoids prefill tasks getting stuck in queue in decode-dominated settings. Achieving the right rate balance requires careful consideration of the number of requests in the prefill queue, the utilization of KV Cache memory blocks in decode GPUs, as well as Service Level Agreements (SLAs) such as Time to First Token (TTFT) and Inter-Token Latency (ITL).

Referring back to Figure 2, each blue dot represents not just a unique combination of prefill and decode model parallel configurations, but also a carefully balanced rate match between prefill and decode GPUs. While this rate matching can be calculated for fixed Input Sequence Length (ISL) and Output Sequence Length (OSL) combinations, real-world deployments present a greater challenge. ISLs and OSLs often vary from one request to another, making consistent rate matching significantly more complex.
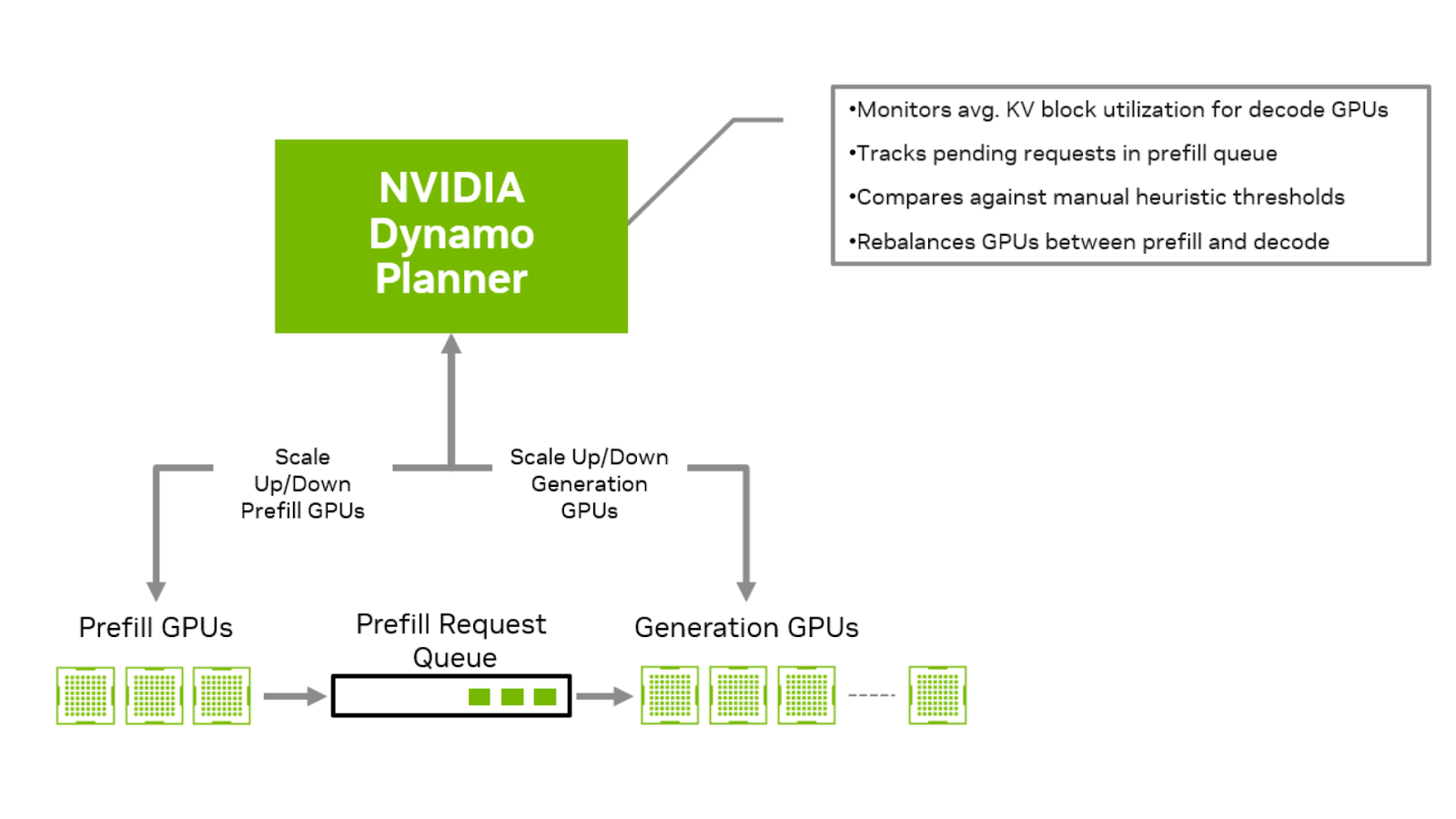
To address this, NVIDIA Dynamo includes a specialized engine, called Planner, that’s designed to automate this process and ensure balanced rate match between prefill and decode for fluctuating workloads. It evaluates prefill queue time, KV Cache memory utilization for decoding, and application SLAs to determine the optimal configuration of GPU resources. It then intelligently decides which types of GPUs to scale, in what direction, and in what proportion, based on the evolving patterns of input and output sequence requests.

Disaggregated serving is beneficial for a wide variety of ISL/OSL traffic patterns, especially for long ISLs. These have prefill heavy workloads that are significantly compromised in aggregated deployments that try to balance decode speed.
In situations where workloads vary between long and short ISLs and OSLs, Dynamo Planner can detect and react to these variations and decide whether to serve incoming requests using traditional aggregated deployments on decode GPUs or serve them using disaggregated serving across both prefill and decode GPUs. It adapts to fluctuating workloads while maintaining GPU utilization and peak system performance.

Leveraging NVIDIA GB200 NVL72 NVLink architecture
In MoE models, each input token is dynamically routed to a small subset of selected experts. In the case of the DeepSeek R1 model, each token is sent to eight experts out of the full pool of 256. These selected experts independently carry out their portions of the inference computation, and then share their outputs with one another and with the shared expert, through an all-to-all communication pattern. This exchange ensures that the final output incorporates the results of the processing of all the selected experts.
To truly harness the performance advantages of MoE models within a disaggregated serving architecture, it is essential to design the decode stage with a wide EP setup. Specifically, this means distributing the experts across GPUs in such a way that each GPU handles a small number of experts. For the DeepSeek R1 model, this is typically around four experts per GPU, which requires 64 GPUs to accommodate the full 256 routed experts during decoding.

However, the all-to-all communication pattern among selected experts introduces significant networking challenges. Because every expert involved in decoding must exchange data with seven others selected for the same token, it becomes critically important that all 256 experts—and consequently the 64 GPUs that host them—operate within the same low-latency, high-bandwidth domain. If the selected experts reside on GPUs that sit on different nodes, the all-to-all communication becomes bottlenecked by slower internode communication protocols, such as InfiniBand.
Ensuring this level of communication efficiency across the 64 GPUs demands a new class of scale-up accelerated computing infrastructure—one that can tightly interconnect all participating GPUs within a single, unified low latency compute domain to avoid communication bottlenecks and maximize throughput.
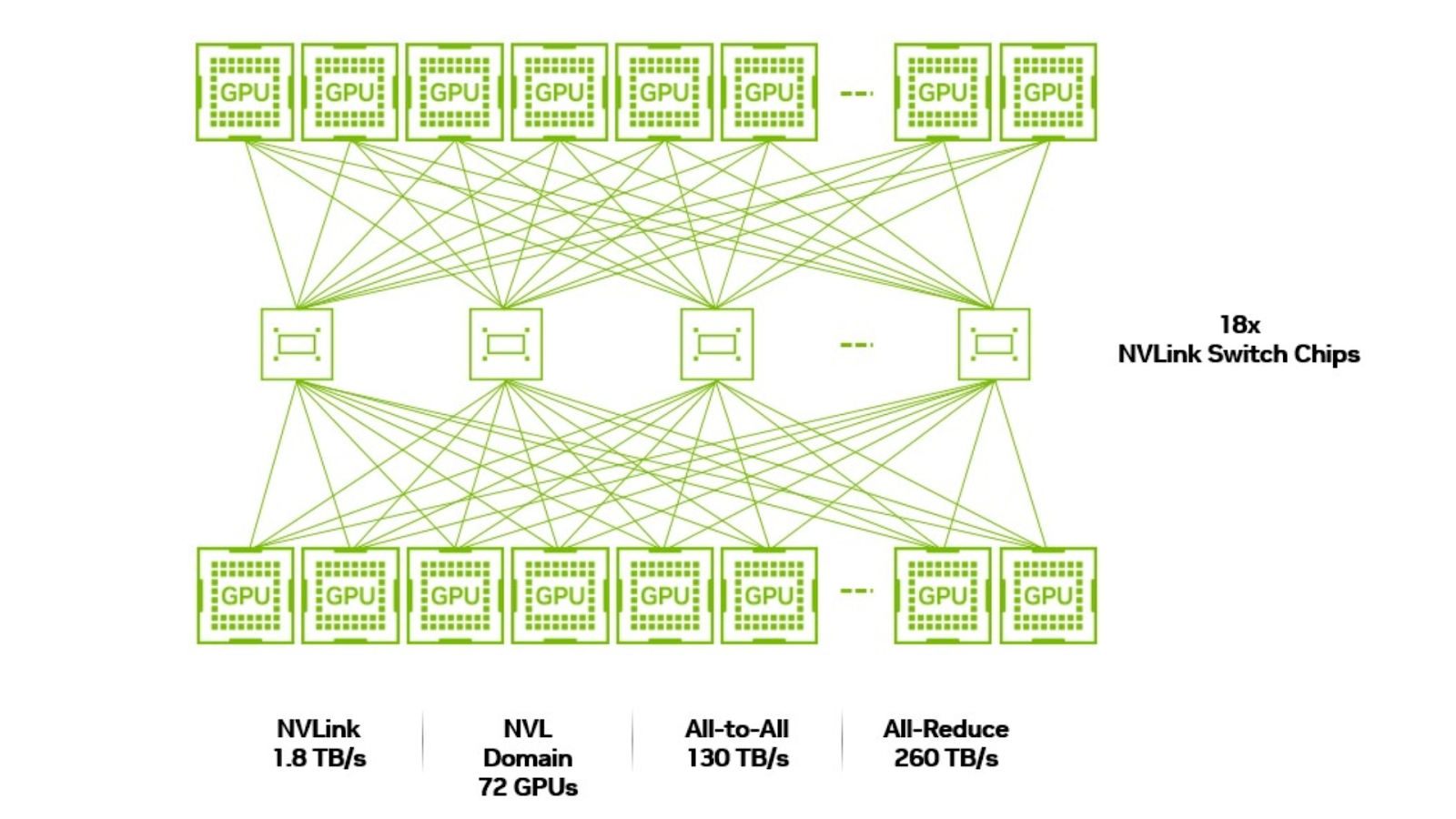
Prior to the introduction of the NVIDIA GB200 NVL72, the maximum number of GPUs that could be connected in a single NVLink domain was limited to eight on an HGX H200 baseboard, with a communication speed of 900 GB per second (GB/s) per GPU. The introduction of the GB200 NVL72 design dramatically expanded these capabilities: The NVLink domain can now support up to 72 NVIDIA Blackwell GPUs, with a communication speed of 1.8 (TB/s)per GPU, 36x faster than 400 Gbps Ethernet standards. This leap in NVLink domain size and speed makes GB200 NVL72 the ideal choice for serving MoE models with wide EP of 64 in disaggregated setup.
Not just MoEs: NVIDIA GB200 NVL72 and NVIDIA Dynamo accelerate dense models
In addition to accelerating MoE models, GB200 NVL72 and Dynamo working together deliver great performance gains when serving traditional dense models like the popular open source Llama 70B model.
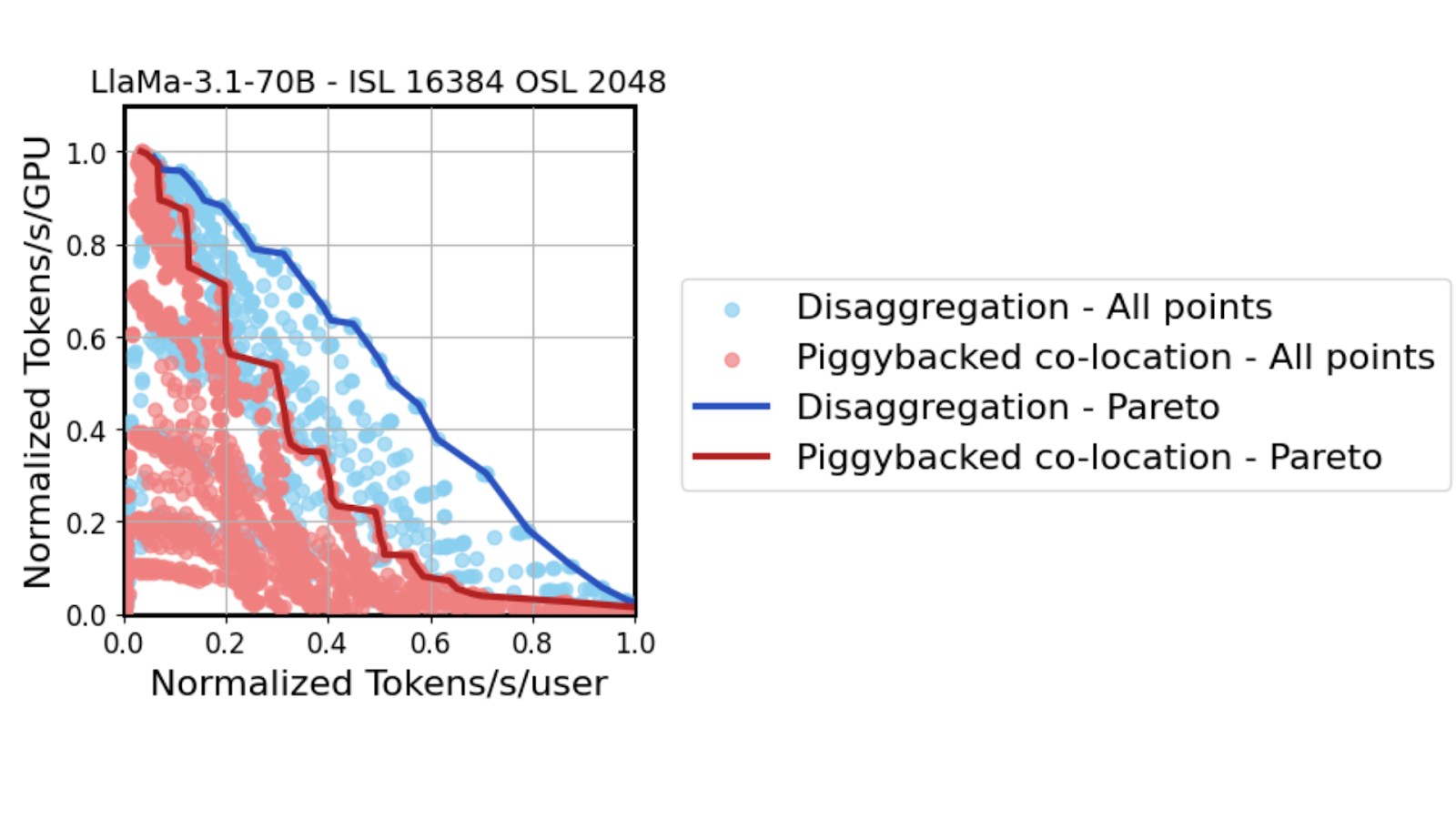
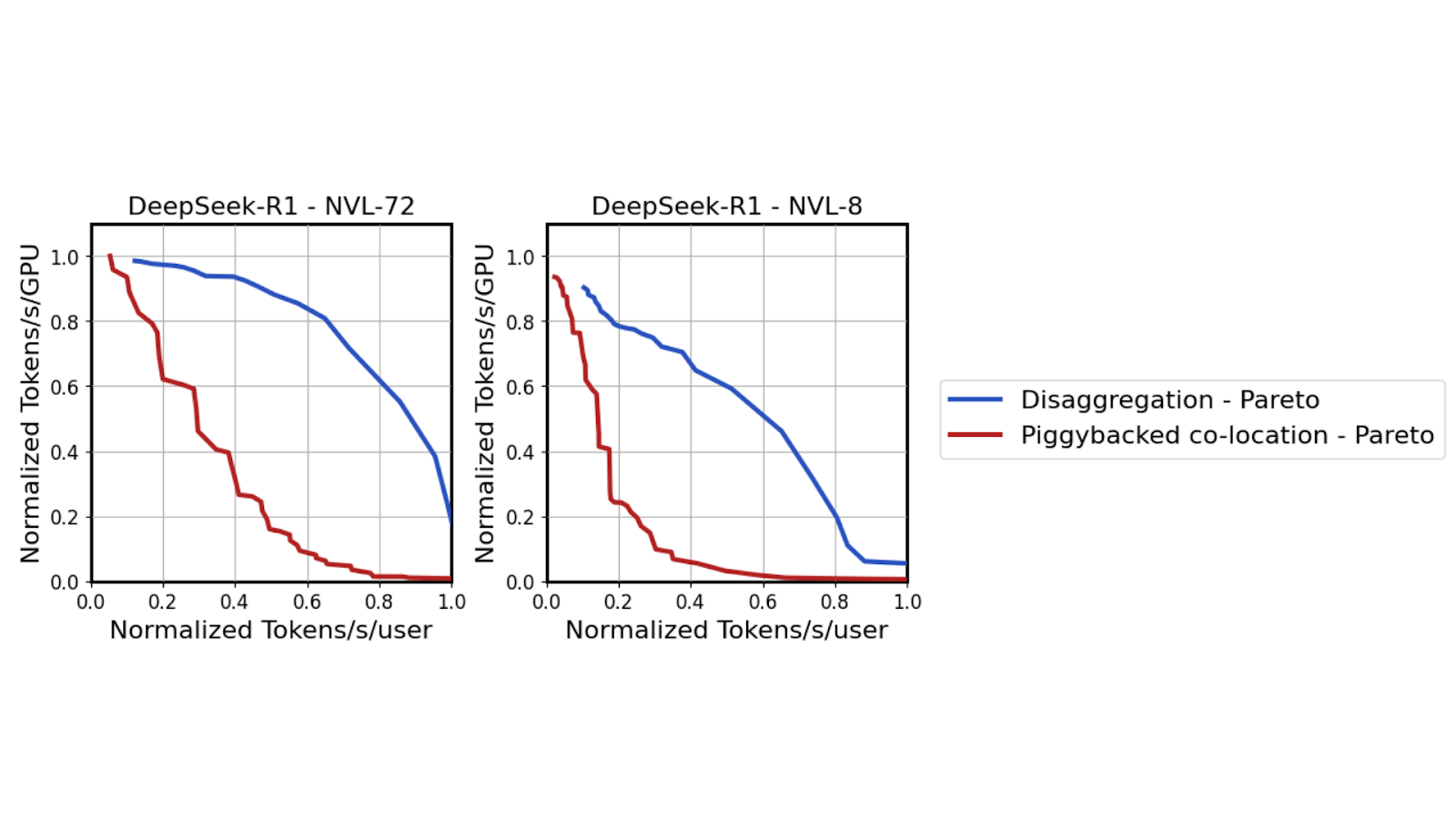
Using the same high fidelity GPU performance simulator serving the Llama 70B model, results show that as TTL constraints tighten (moving from left to right on the x-axis), tensor parallelism must be scaled from two GPUs to 64 GPUs. While both co-located and disaggregated serving favor high tensor parallelism under tight TTL SLAs, disaggregated decoding is able to pursue this strategy more aggressively.
Freed from the need to balance math-heavy prefill performance with decoding speed, Dynamo disaggregated decode setups can better adapt to tightening latency demands. Once again, the scale-up architecture of the GB200 NVL72 allows all GPUs that are part of the TP decode deployment to communicate using all-reduce at speeds up to 260 TBps. That leads to increased throughput performance in the same medium-latency regime of up to 3x.
Conclusion
The combination of NVIDIA Dynamo and NVIDIA GB200 NVL72 creates a powerful compounding effect that optimizes inference performance for AI factories that are deploying MoE models, such as DeepSeek R1 and the newly released Llama 4 models in production. NVIDIA Dynamo simplifies and automates the complex challenges of disaggregated serving for MoE models by handling tasks like prefill and decode autoscaling, as well as rate matching.
NVIDIA GB200 NVL72, meanwhile, offers a unique scale-up architecture capable of accelerating the all-to-all communication requirements of wide expert-parallel decode setups in disaggregated MoE deployments. Together, they enable AI factories to maximize GPU utilization, serving more requests per investment and driving sustained margin growth.
For a deeper dive into the technical details of deploying DeepSeek R1 and Llama models on large-scale GPU clusters using disaggregated serving, please refer to our technical white paper available here.
How NVIDIA GB200 NVL72 and NVIDIA Dynamo Boost Inference Performance for MoE Models