



In the field of automotive vehicle software development, more large-scale AI models are being integrated into autonomous vehicles. The models range from vision AI models to end-to-end AI models for autonomous driving. Now the demand for computing power is sharply increasing, leading to higher system loads that can have a negative impact on system stability and latency.
To address these challenges, Programmable Vision Accelerator (PVA), a low-power and efficient hardware engine available on NVIDIA DRIVE SoCs, can be used to improve energy efficiency and overall system performance. By using PVA, tasks typically handled by the GPU or other hardware engines can be offloaded, thereby reducing their load and enabling them to manage other critical tasks more efficiently.
In this post, we provide a brief introduction to the PVA hardware engine and the SDK on the DRIVE platform. We showcase the typical use cases of the PVA engine in the computer vision (CV) pipeline, including preprocessing, postprocessing, and other CV algorithms, highlighting its effectiveness and efficiency. Finally, as an example, we detail how NIO uses the NVIDIA PVA engine and the optimized algorithms)within its data pipeline to offload GPU or video image compositor (VIC) tasks and enhance the overall performance of the autonomous vehicle systems.
Overview of PVA hardware
The PVA engine is an advanced very long instruction word (VLIW), single instruction multiple data (SIMD) digital signal processor. It is optimized for the tasks of image processing and computer vision algorithm acceleration.
PVA provides excellent performance with extremely low power consumption. PVA can be used asynchronously and concurrently with the CPU, GPU, and other accelerators on the DRIVE platform as part of a heterogeneous compute pipeline.
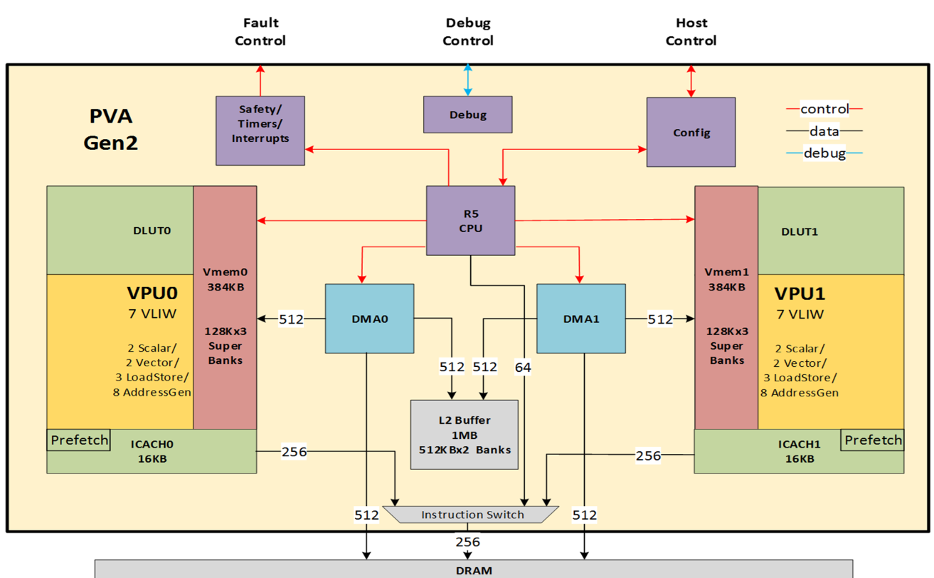
There is one PVA instance in the CV cluster on NVIDIA Orin, which is a high-performance system-on-chip (SoC) designed for advanced AI applications, particularly in autonomous vehicles and robotics.
In each PVA, there are two vector processing subsystems (VPS). Each VPS includes the following:
- 1 vector processing unit (VPU) core
- 1 decoupled look-up unit (DLUT)
- 1 vector memory (VMEM)
- 1 instruction cache (I-cache)
The VPU core is the main processing unit. It is a vector SIMD VLIW DSP optimized for computer vision. It fetches instructions through the I-cache, and accesses data through the VMEM.
The DLUT is a specialized hardware component developed to enhance the efficiency of parallel lookup operations. It enables parallel lookups using a single copy of the lookup table by executing these lookups in a decoupled pipeline, independent of the primary processor pipeline. By doing so, the DLUT minimizes memory usage and enhances throughput while avoiding data-dependent memory bank conflicts, ultimately leading to improved overall system performance.
VPU VMEM provides local data storage for the VPU, enabling efficient implementation of various image processing and computer vision algorithms. It supports access from outside-VPS hosts such as DMA and R5, facilitating data exchange with R5 and other system-level components.
The VPU I-cache supplies instruction data to the VPU when requested, requests missing instruction data from system memory, and maintains temporary instruction storage for the VPU.
For each VPU task, R5 configures DMA, optionally prefetches the VPU program into VPU I-cache, and kicks off each VPU-DMA pair to process a task. Orin PVA also includes an L2 SRAM memory to be shared between the two sets of VPS and DMA.
Two DMA devices are used to move data among external memory, PVA L2 memory, the two VMEMs (one in each VPS), R5 TCM (tightly coupled memory), DMA descriptor memory, and PVA-level config registers.
In a lightly loaded system, two parallel DMA accesses to DRAM can achieve a read/write bandwidth of up to 15 GB/s each. In a heavily loaded system, this bandwidth can reach up to 10 GB/s each.
Regarding computing capacities, the INT8 GMACs (Giga Multiply-Accumulate Operations per Second) is 2048, excluding the DLUT. The FP32 GMACs is 32 per PVA instance.
Introduction to the PVA SDK
Similar as the CUDA toolkit is to GPUs, the NVIDIA PVA SDK is designed for crafting computer vision algorithms that harness the PVA hardware’s capabilities. The PVA SDK provides runtime APIs, tools and tutorials for the development, deployment, and safety certification of CV and DL/ML algorithms. It offers a seamless build-to-deploy framework, enabling the cross-compilation of code into a binary executable on the Tegra PVA.
The PVA SDK bolsters software development with a variety of resources:
- A comprehensive getting started guide
- An x86 native emulator that mimics a real VPU, enabling the development and functional debugging of VPU kernels on x86-64 platforms
- A full suite of code generation tools including an optimizing C/C++ compiler, debuggers, and integrated development environment
- Profiling utilities, such as NVIDIA Nsight Systems for visual performance analysis and APIs for detailed VPU code performance metrics
- Step-by-step tutorials introduce PVA concept by concept, ranging from basic examples to advanced optimizations for VPU, DMA, and interop with other Tegra engines
- Extensive documentation and reference manuals that provide detailed information on VPU intrinsics, enabling you to write optimized code while abstracting the complexities of DMA programming
The PVA SDK provides numerous ready-to-use algorithms to support common computer vision use cases in autonomous driving and robotics. It enables you to use these algorithms by default (with access to the source code) in a production environment or use the PVA SDK features to develop custom algorithms.
NVIDIA has predeveloped many algorithms based on the PVA SDK according to the common CV use cases. Use the PVA algorithms, with access to the code, in production or just use the different algorithms as a reference to develop your own valuable algorithms.
Typical PVA use cases
Many developers of autonomous vehicles are facing the challenge of insufficient computing resources on their SoCs, resulting in high loads on the CPU, GPU, VIC, and DLA. To address this issue, the PVA hardware is being considered for offloading processing tasks from these heavily used hardware engines on the SoC.
Here are some examples of processing tasks that can be offloaded:
- Image processing: Some image-processing and CV tasks can be ported to the PVA to offload GPU, CPU, VIC, and even DLA.
- Deep learning operations: Within deep learning networks, certain layers or computationally intensive operators (such as ROI aligns) can be offloaded to the PVA. In specific cases, small deep-learning networks can be entirely ported to the PVA.
- Math computation: The PVA, being a vector SIMD VLIW DSP, can handle math computations efficiently, such as matrix computation, FFT, and so on.
The following two use cases are offered in detail for reference:
- Offloading preprocessing and postprocessing in AI pipelines to PVA
- Moving pure CV or compute-bound pipelines to PVA
Offloading preprocessing and postprocessing in AI pipelines to PVA

This is a typical use case of the CV pipeline. The input images come from either a live camera in real-time scenarios or a decoder in offline scenarios. The pipeline consists of three stages:
- Preprocessing
- AI inference
- Postprocessing
The PVA hardware engine can play a crucial role in all stages of the CV pipeline, from preprocessing to postprocessing, ensuring efficient and effective handling of image processing and computer vision tasks.
Preprocessing
Preprocessing involves basic CV tasks to align or normalize the input for the model. This includes operations such as remapping (undistortion), cropping, resizing, and color conversion (from YUV to RGB).
In some cases, when the images are from NVDEC (the decoder hardware engine on the Tegra SoC), the image layout is block linear. In that case, more steps are needed in the preprocessing stage to convert the block linear image to a pitch linear image.
The PVA hardware engine is well-suited for these tasks. However, in memory-bound cases, consider merging adjacent PVA operations to fully use the PVA’s computational power.
AI inference
AI inference performs the core CV tasks required by business needs based on the state-of-the-art AI models. This step can be executed on the GPU or DLA (Deep Learning Accelerator) for better performance.
The PVA runtime APIs support both NvSciSync and native CUDA streams, enabling efficient execution of heterogeneous pipelines involving GPU or DLA without incurring the latency associated with reverting to the CPU for scheduling.
Depending on the use case, the AI model could be YOLO or R-CNN for object detection, logistic regression or k-nearest neighbor (KNN) for classification, and any other models, and so on.
Post-processing
Postprocessing refines the detection results. This may involve using a median filter to remove outliers, blending operations to fuse different candidates, or applying non-maximum suppression (NMS) to select the best target. The PVA hardware can effectively handle these tasks.
Moving pure CV or compute-bound pipelines to PVA
This is a more specific and complex use case, where all steps can be performed on the PVA. It primarily involves detecting and tracking feature points in input images or computing sparse optical flow in certain scenarios:
- An image pyramid extends the image along the scale space.
- A specific detection algorithm identifies feature points or corners in the image.
- A tracking algorithm tracks these feature points frame by frame.
Compared to the previous use case, this scenario differs in key aspects:
- Compute-bound processing: Each step of data processing is compute-bound and involves processing 2D images. These algorithms can be well-vectorized and executed highly efficiently on the PVA hardware. Most importantly, the computation capability of PVA is fully used.
- Tightly coupled steps: There is an additional data loop that transfers tracking information back to previous steps to refine subsequent tracking results. This makes the steps more tightly coupled.
- Pure CV pipeline: This use case is a pure computer vision pipeline that does not involve machine learning networks. Each step is predictable and explainable, focusing solely on traditional CV algorithms.
By using PVA for these tasks, you can alleviate the load on the GPU, VIC, CPU, and DLA, leading to a more stable and efficient system.
NIO’s data pipeline optimization
NIO Inc. is a prominent Chinese multinational automobile manufacturer, specializing in the design, development, and production of premium smart electric vehicles (EVs).
The following data pipeline from NIO involves de-identifying, masking, or replacing interested regions and objects in video streams from live cameras or H.264 videos using specialized algorithms and techniques.
Original scheme of the data pipeline
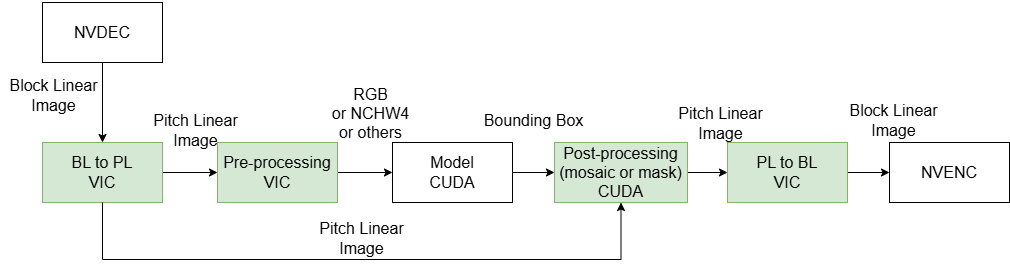
Figure 4 represents the original version of NIO’s data pipeline. The NVDEC is used to decode H264 videos, producing block linear YUV images. As block linear is an internal format specific to NVIDIA, external users cannot process these images directly. The VIC engine is used to convert the block linear images to pitch linear format for further processing.
Next, a color conversion (from YUV to RGB) is performed using the VIC engine to produce RGB images. These images are then analyzed by AI models to detect interested objects. After the AI model generates bounding boxes for the object, postprocessing steps using VIC or CUDA apply mosaics or masks to the original YUV pitch linear images.
Finally, the processed frames are converted back from pitch linear to block linear format using the VIC engine and then encoded back to H264 videos with NVENC.
Replacing CV operations with PVA
In NIO’s case, both the GPU and VIC are heavily loaded. According to this pipeline, several CV operators are involved, including the following:
- Layout conversion between the block linear and pitch linear formats
- Color conversion from YUV to RGB
- Mosaicing and masking
These operators can be offloaded to the PVA to save resources on the GPU and VIC.
Both layout conversion and color conversion are memory-bound tasks for the PVA, with DMA bandwidth being the bottleneck. Other computing resources in the PVA might be used for mosaicing or masking based on the bounding box and the YUV PL image.
To further accelerate execution, you can also run PVA algorithms in parallel, as each PVA instance contains two VPUs and each VPU has a standalone DMA controller for data exchange with DRAM.
Several other techniques can also be employed when implementing PVA kernels to enhance overall performance. These include the DLUT, hardware-based loop address generation (AGEN), ping-pong buffers, and loop unrolling.
Data pipeline optimization
In a traditional data processing pipeline, latency may arise from two sources:
- Overhead of copying data between different function modules or hardware accelerators, such as PVA and DLA in this use case.
- Additional synchronization overhead required for performing and synchronizing multiple algorithmic processes.
These overheads can be reduced by using the NvStreams framework provided by the NVIDIA DriveOS SDK. The PVA hardware accelerator can work efficiently with NvStreams using the NvSci interoperability APIs in the PVA SDK to achieve zero-copy data transitions and asynchronous task submission to minimize the overhead.
Zero-copy interface
Different hardware components (for example, PVA and CPU) and applications have their own access restrictions or requirements for memory buffers. To achieve the goal of zero-copy, a unified memory architecture enables accelerators and different applications to share the same physical memory on the NVIDIA DRIVE SoC.
Before allocating the memory buffer, detailed requirements are collected and reconciled to ensure the allocated memory buffer is shareable across necessary modules. This feature is realized through the NvStreams APIs.
After the shareable memory buffer is successfully allocated, data transitions between different hardware modules or applications can work in a zero-copy manner. This solution applies to scenarios involving inter-process communication (IPC) or cross-virtual machines (VMs). For data transfers between chips, high-speed PCIe can be used under the same NvStreams framework.
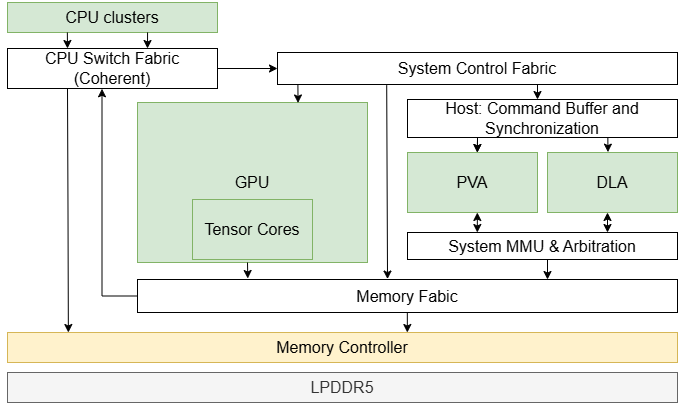
Hardware accelerator-based scheduling
NIO’s data pipeline incorporates multiple hardware accelerators and you can use NvSciSync to manage synchronization between these engines. NvSciSync, part of the NVIDIA NvStreams library, coordinates the execution of operations across different hardware components by managing synchronization objects.
First, insert the sync points between tasks running on the accelerators. When a task begins, subsequent hardware accelerators wait at the sync point until the preceding tasks are completed. When a task finishes, its corresponding hardware accelerator releases the sync point, automatically triggering the next accelerator to proceed with its task. This process minimizes CPU involvement, requiring only some initial setup, and ensures efficient synchronization across hardware engines.
PVA task level–based scheduling
In the original pipeline, all task submissions and synchronizations are controlled by the CPU one by one. That means the CPU submits the tasks to the computing engines and then waits synchronously on each of the algorithm tasks to be completed.
The PVA supports submitting multiple tasks at one time and waiting only on the last task. All submitted PVA tasks are computed in the specified orders until all tasks are completed. Submitting multiple tasks in a batch optimizes performance by reducing the CPU load associated with PVA task submissions. This frees up the CPU for other valuable tasks and decreases overall system latency.
Using the PVA SDK, you can also specify scheduling strategies for PVA algorithms to fully leverage the two VPUs on a PVA instance. For example, you can specify that certain algorithms be performed on a single VPU.
When using both VPUs, if there are sequential requirements between tasks, you can set the tasks to be performed one after the other on the two VPUs. If there are no sequential requirements, PVA tasks are performed as soon as the VPUs are free. This significantly reduces the multiple-task execution latency.
Production readiness
Figure 6 shows the production-ready NIO data pipeline after replacing the CV operations with PVA and porting the DL model to the DLA engine. For more information, see Deploying YOLOv5 on NVIDIA Jetson Orin with cuDLA: Quantization-Aware Training to Inference.

In this optimized pipeline, the PVA and DLA solution effectively meets the business requirements. This approach is feasible and highly efficient. As a result, overall GPU resource usage is reduced by 10%, and the VIC engine is freed up for other high-priority tasks within the system. There is no need to pre-allocate extra memory for temporary variables during block linear and pitch linear conversions, leading to significant memory savings.
According to the NIO internal review, the PVA operates at about 50% load on one VPU instance when running this pipeline in the system. As one PVA contains two VPUs, the total load of PVA is about 25% in the NIO data pipeline. This shows that the PVA still has available computational capacity for additional tasks within this pipeline.
Further optimization
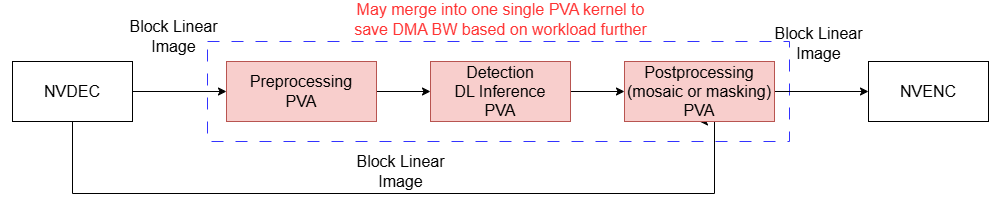
To further optimize this pipeline, you can take one or both of the following steps:
- Use the PVA to replace the DLA with a simple deep learning model, as the PVA is currently only about 25% utilized. Internal tests have shown that a Yolo-Fastest network can be successfully ported to the PVA, detecting objects as expected.
- Consider merging the preprocessing, deep learning inference, and postprocessing stages into one single PVA kernel to reduce overall DMA bandwidth by eliminating the need for additional DMA transmissions between kernels.
Conclusion
The PVA-based optimization solution significantly improves the performance of the NIO pipeline and is extensively used in NIO’s mass production vehicles. By offloading tasks to the PVA, GPU computational resources can be freed up, enabling an increase in deep learning TOPs and enabling you to implement more complex deep learning networks.
NIO is actively developing more efficient algorithms on the PVA using the PVA SDK to leverage the additional computational capabilities of the NVIDIA DRIVE platform, thereby enhancing the intelligence and competitiveness of their products.
In conclusion, the PVA provides powerful tools for addressing computations in autonomous vehicle development, enabling more efficient and effective processing of complex visual tasks and improving overall system performance.
Optimizing the CV Pipeline in Automotive Vehicle Development Using the PVA Engine