



The energy industry’s digital transformation requires a substantial increase in computational demands for key HPC workloads and applications. This trend is exemplified by advanced seismic imaging methodologies such as reverse time migration (RTM) and full waveform inversion (FWI), where doubling maximum frequency can produce a 16x increase in computational workload. Similarly, in reservoir simulation, a reduction in grid discretization by a factor of two across all three dimensions can amplify computational requirements by a factor of eight.
These developments highlight an urgent need for flexible and scalable computing resources tailored to meet evolving HPC demands in the energy industry. Cloud computing is a viable solution to accommodate increasing computational requirements. However, achieving optimal performance and cost for cloud computing requires significant engineering efforts to modernize existing HPC applications.
The AWS Energy HPC Orchestrator provides an integrated environment to overcome those challenges. This open industry platform and marketplace ecosystem, developed in collaboration with AWS and leading energy companies, and the NVIDIA Energy Samples available directly from NVIDIA focuses on enabling interoperability between processing modules to deliver optimized scalability, flexibility, and economics. It also provides a series of pre-optimized, cloud-native HPC templates to ease modernization engineering efforts and create an open HPC marketplace where every participant can focus on their differentiating technology.
In this post, we detail how to integrate the NVIDIA Energy Samples, used to build derivative solutions on top of the AWS Energy HPC Orchestrator. This platform uses an AWS Cloud-optimized template to quickly build a cloud-native seismic application, and scale it with hundreds of NVIDIA-powered instances.
Designing the AWS Energy HPC Orchestrator
The AWS Energy HPC Orchestrator reference architecture contains the following essential components:
- A system that enables the following:
- Orchestration of HPC applications of different kinds that use a common storage system.
- Enterprise functionalities, such as user, project, and data management.
- An ecosystem of HPC applications that are compatible with the AWS Energy HPC Orchestrator and distributed through a marketplace.
- A set of data standards to allow the interoperability (data exchange) between HPC applications.
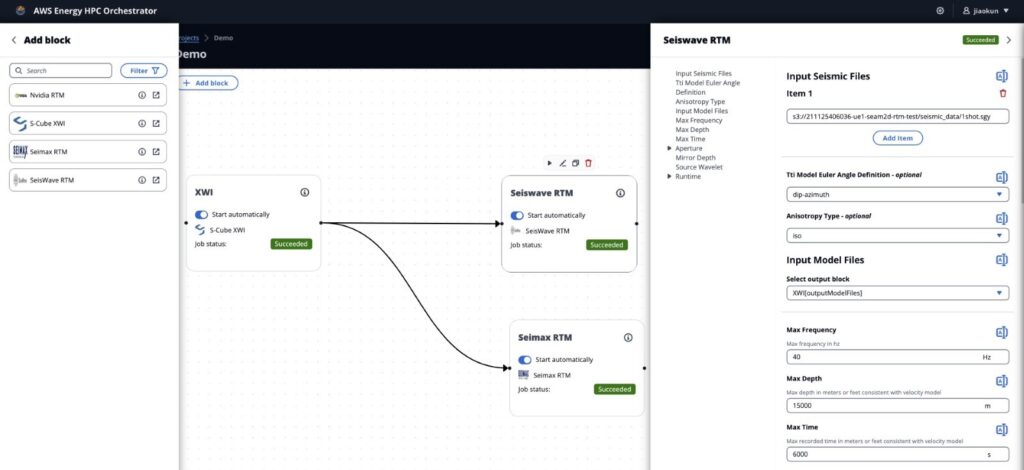
Extensions
Extensions are plug-ins to the system that provide domain-specific capabilities. For example, you can have different extensions providing implementations of algorithms, such as RTM or FWI. Extensions are required to implement the event-based protocols defined by the core.
RTM template
Templates are reusable for a class of algorithms and encapsulate best practices for running these algorithms on AWS.
The RTM template is designed to transform a traditional RTM application for seismic processing into a modernized, cloud-native application. This design capitalizes on robust AWS services to boost scalability, resilience, and operational efficiency of high-end seismic imaging algorithms.
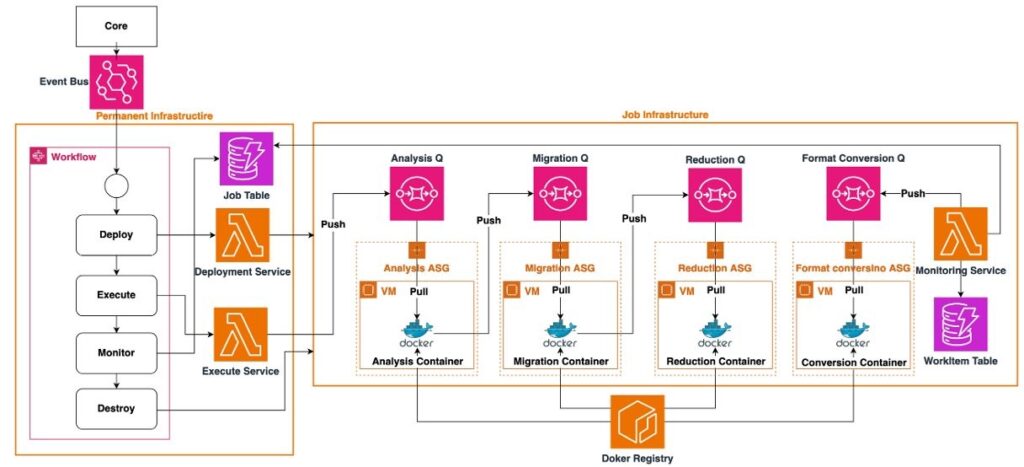
The execution of the RTM algorithm unfolds within the dynamic backend, segmented into four distinct, decoupled microservices, each one specialized for a task of the RTM algorithm:
- Analysis
- Migration
- Reduction
- Converter
Analysis Service
This microservice starts the workflow by procuring a work item, usually a pointer to a seismic file’s location (object store URI), from the input data queue. It then scans the file’s header or its metadata to ascertain the number of shots it contains.
Subsequently, for every shot detected, the Analysis Service formulates individual work item details and dispatches this metadata into the migration queue, fragmenting the task into smaller, independent processing units.
Migration Service
The Migration Service pulls work item details from the migration queue. It loads models and reads data from the input seismic data file. Then, it solves the forward wave equation and the adjoint wave equation, yields a 3D image, and uploads to the object store. Afterward, a corresponding reduction work item is pushed into the reduction queue for subsequent stacking.
Reduction Service
This service activates by retrieving two work items from the reduction queue. It retrieves two corresponding images from the object store and stacks them into a single image. This stacked image is re-uploaded to the object store, and a work item is re-enqueued to the reduction queue.
This cycle persists until the reduction queue is left with a singular, composite work item, denoting the completion of the RTM process for the entire dataset.
Converter Service
This service converts the final stacked image into the appropriate final format.
Queuing and scaling
The indirect interaction between microservices through a queuing system not only enforces the system’s resilience and fault tolerance but also enables autonomous scaling of each service. Through an auto-scaling group, services dynamically adjust in scale, driven by the number of work items or seismic shots queued, ensuring optimal resource allocation.
By using cloud-native services, such as serverless compute for real-time monitoring and event-driven operations, the architecture eschews traditional HPC orchestration methods such as MPI or Slurm, instead offering a more agile and robust method for implementing RTM in the cloud.
The workflow of each service is asynchronous, preventing any single point of failure or single operation from causing a bottleneck. The queue-based communication decouples services for enhanced fault tolerance and promotes a highly asynchronous shot processing system. The asynchronicity ensures scalability and further strengthens the fault tolerance of the system.
Each microservice operates autonomously and scales up or down, according to the queued workload. This design guarantees resilience against individual component failures and provides flexibility to efficiently manage various loads.
The asynchronous and resilient nature of this architecture also offers a significant edge in both performance and cost optimization using AWS Spot Instances.
Different instance types can be allocated to various services, striking an optimal balance between cost and performance. For example, Analysis Service can use general-purpose instances. Migration Service can use HPC instances, while Reduction Service may opt for network-optimized instances to suit its workload.
Integrating NVIDIA Energy Samples
RTM is an advanced seismic imaging technique widely used in the field of geophysics, particularly in oil and gas exploration. RTM plays a crucial role in creating accurate subsurface images. The technique involves solving the seismic waves propagating through a computational model of the Earth’s subsurface, allowing geophysicists to generate high-resolution images of geological structures.
Unlike traditional migration methods, RTM can handle complex velocity models and sharp contrasts in the subsurface, making it invaluable for imaging beneath areas with complex geology, such as salt bodies or steeply dipping layers.
NVIDIA Energy Samples is a collection of reference implementations of key algorithms in seismic processing such as RTM, Kirchoff, and FWI, all of which have been written in CUDA and tuned for maximum gain on NVIDIA GPUs. The algorithms are ready to run on cloud platforms, but cannot be considered production-grade implementations. The samples, available directly from NVIDIA, make it easy for geophysicists to produce full-featured and highly performant implementations by including their own customizations unique to each geophysics group.
RTM is a computationally intensive process that benefits significantly from accelerated computing powered by NVIDIA. NVIDIA Energy Samples is a set of sample codes that demonstrate how to harness the full power of NVIDIA GPUs for key seismic processing algorithms. Even though they do not provide a full production solution, the samples enable geophysicists to turn their unique RTM algorithms into high-performing GPU code.
AWS provides a cloud-native, optimized RTM template as Python code. It is decoupled into four microservices: Analysis, Migration, Reduction, and SegyConverter.
With the help of the AWS RTM template, you use the standard Analysis Service, Reduction Service, and SegyConverter Service without any code modification. These services are written to work with Amazon S3 natively and pre-optimized to achieve optimal performance.
There are a few modifications to the Migration Service to enable NVIDIA Energy Samples to integrate with AWS Energy HPC Orchestrator (EHO):
- Parameter conversion
- Model handling
- Data handling
Parameter conversion
EHO has a web interface to pass parameters to the HPC application in a JSON format. However, the RTM sample from NVIDIA Energy Samples is taking the parameter as plain ASCII format. You must write a custom Python function to convert the parameter JSON into ASCII format:
#!/usr/bin/python3import jsonfrom sys import *def json2par(data, local_shot_file, local_modelfiles, local_img_fname, dt, nt, ntr): strpar="" # hardcode part strpar+=f"storageFileName=/scr\n" strpar+=f"imagingData= {local_img_fname}\n" strpar+=f"InputData= {local_shot_file}\n" strpar+=f"InputHeaders= {local_shot_file}.hdr\n" strpar+=f"NTraces= {ntr}\n" strpar+=f"Nsamples= {nt}\n" strpar+=f"SRate= {dt}\n" strpar+=f"FirstShotSelect= 0\n" strpar+=f"LastShotSelect= 0\n" strpar+=f"velocityData= {local_modelfiles['vp']}\n" strpar+=f"epsilonData= {local_modelfiles['epsilon']}\n" strpar+=f"deltaData= {local_modelfiles['delta']}\n" strpar+=f"thetaData= {local_modelfiles['dip']}\n" strpar+=f"phiData= {local_modelfiles['azimuth']}\n" # jobrelated part sdgp = data["Standardized Geophysical Parameters"] rp = data["Runtime Parameters"] spgp = data["Specialized Geophysical Parameters"] srp = data["Specialized Runtime Parameters"] gp = data["Grid Parameters"] strpar+=f"ngpus={srp['nGPUs']}\n" strpar+=f"storage={srp['LocalComputeStorage']}\n" strpar+=f"nb_quants_bitcomp={srp['nb_quants_compression']}\n" strpar+=f"cyclesSkip4Imaging={spgp['imagingStep']}\n" strpar+=f"noperator={spgp['fdOperator']}\n" strpar+=f"weightPower={spgp['weightPower']}\n" strpar+=f"inputDataMultiply={spgp['inputDataMultiply']}\n" strpar+=f"dtPropagation={spgp['dtPropagation']}\n" strpar+=f"minValueOfVelocity={spgp['minVelocity']}\n" strpar+=f"maxValueOfVelocity={spgp['maxVelocity']}\n" strpar+=f"aperture_inline={sdgp['aperture']['inlineAperture']}\n" strpar+=f"aperture_xline={sdgp['aperture']['xlineAperture']}\n" |
Model handling
The next step involves modifying the download_and_cache_models function. This function is responsible for downloading the seismic velocity models and caching them on an NVIDIA GPU instance until the RTM process is complete. Because the RTM sample from NVIDIA Energy Samples requires models in a raw float binary format, it is necessary to convert the downloaded SEGY format models.
# Overwrite this method to post-process the model files after downloaddef download_and_cache_models(self, job_info, tmpdirname) -> dict[str, str]: ‘’’ See base class for more details ‘’’ # result = super().download_and_cache_models(job_info, tmpdirname) local_model = {} for input_model in job_info["module_configuration"]["Input"]["InputModelFiles"]: url = urlparse(input_model[‘modelFile’]) local_segy_file = f"{tmpdirname}/{os.path.split(url.path)[1]}" local_file = f"{local_segy_file}.bin" local_file_hdr = f"{local_segy_file}.bin.hdr" local_file_att = f"{local_segy_file}.bin.attributes.txt" local_model[input_model['property']]=local_file if not os.path.exists(local_file): object_path = url.path.lstrip('/') self.download_file(url.hostname, object_path, local_segy_file) trace_batch=1000 process_segy.process_segy_file(local_segy_file, trace_batch, local_file, local_file_hdr, local_file_att) os.remove(local_segy_file) return local_model |
Data handling
Next, modify the download_shot_file function provided by the AWS RTM template to enable partial downloads of seismic shot data from an S3 object. The RTM sample from NVIDIA Energy Samples requires seismic data to be in a specific format, consisting of raw binary data accompanied by a raw binary header. The raw binary data contains only the seismic measurements, while the binary header includes seven floating-point values per trace:
- Source x, y, and z (elevation) coordinates
- Receiver x, y, and z (elevation) coordinates
- An additional float to indicate trace validity (1 indicates invalid and 0 indicates valid)
# Overwrite this method to customize the download of shot filedef download_shot_file(self, data_bucket_name:str, data_object_key:str, start_offset:int, end_offset:int, local_shot_file:str): ''' See base class for more details ''' local_shot_segy_file=f"{local_shot_file}.segy" ranges=[[0,3599], [start_offset, end_offset-1]] t = S3CRTFileTransfer(18) t.download_parts2file(data_bucket_name, data_object_key, local_shot_segy_file, ranges) trace_batch=1000 local_shot_file_hdr = f"{local_shot_file}.hdr" local_shot_file_att = f"{local_shot_file}.attributes.txt" process_segy.process_segy_file(local_shot_segy_file, trace_batch, local_shot_file, local_shot_file_hdr, local_shot_file_att) os.remove(local_shot_segy_file) return |
Next, modify the migration_single_shot function to execute the RTM sample from NVIDIA Energy Samples by invoking it with the generated ASCII parameter file using a Python sub-process.
# Overwrite this method to customize the download of shot filedef migrate_shot_local(self, job_info, working_dir:str, local_shot_file:str, shot_id:int, local_model_files:dict[str,str], local_img_fname:str) -> bool: datattfile = open(f"{local_shot_file}.attributes.txt", "r") lines = datattfile.readlines() datattfile.close() t,dt=lines[0].split(":") dt=str(float(dt.lstrip().rstrip()/1000.0) t,nt=lines[1].split(":") nt = nt.lstrip().rstrip() lssize = os.stat(local_shot_file).st_size ntr=str(int(lssize/int(nt)/4)) ''' See base class for more details ''' jsondata = job_info['module_configuration'] strpar = json2par.json2par(jsondata, local_shot_file, local_model_files, local_img_fname, dt, nt, ntr) parfname = "/scr/parfile/singleshot" parfile = open(parfname, "w") parfile.write(strpar) parfile.close() cmd = f"LD_LIBRARY_PATH=/usr/local/cuda-12.5/targets/x86_64-linux/lib:/work/nvcomp_3.0.4/lib /work/rtm parfile= {parfname} >& /scr/run.log" logging.info("running RTM cmd: %s", cmd) logging.info("Starting Nvidia RTM migration...") subprocess.run(cmd, cwd=working_dir, shell=True, text=True, check=True) logging.info("Migration ended.") return True |
Then, package the migration service code, along with RTM sample from NVIDIA Energy Samples and required libraries, into a Docker image, which is subsequently pushed to Amazon Elastic Container Registry (ECR). This enables the AWS RTM template to automatically scale the RTM sample from NVIDIA Energy Samples across hundreds of NVIDIA GPU instances.
Building NVIDIA Energy Samples
Here’s how to build the RTM sample from NVIDIA Energy Samples and AWS image used for the NVIDIA GPU instance.
There are a few prerequisites:
- Download and install nv_comp library from the NVIDIA Developer web portal.
- Use the AWS deep learning AMI, which is preinstalled with all necessary NVIDIA CUDA libraries and the NVIDIA CUDA GPU Driver.
Here’s the homescreen for Amazon Linux 2, supported on multiple NVIDIA CUDA versions, drivers, and Amazon EC2 instances.
, #_ ~\_ ####_ Amazon Linux 2 ~~ \######\ ~~ \#######| AL2 End of Life is 2025-06-30. ~~ ####/ --- ~~ V~' '~-> ~~~ / ~~._. _/ _/_/_/ _/m/'A newer version of Amazon Linux is available! Amazon Linux 2023, GA and supported until 2028-03-15.27 package(s) needed for security, out of 37 availableRun "sudo yum update" to apply all updates.=================================================================AMI Name: Deep Learning Base OSS Nvidia Driver AMI (Amazon Linux 2) Version 65Supported EC2 instances: G4dn, G5, G6, Gr6, P4d, P4de, P5NVIDIA driver version: 535.183.01CUDA versions available: cuda-11.8 cuda-12.1 cuda-12.2 cuda-12.3Default CUDA version is 12.1 |
Modify the CMakelists.txt to set the arch correctly according to the NVIDIA GPU instance.
set(CMAKE_CUDA_FLAGS “${CMAKE_CUDA_FLAGS} -gencode arch=compute_75,code=sm_75 ”) |
Then, use CMake to build the RTM sample from NVIDIA Energy Samples and generate an RTM executable binary, which can be integrated to EHO.
0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loadsptxas info : Used 14 registers, 496 bytes cmem[0]ptxas info : Compiling entry function '_Z13add_receiversPfPN6common16SeismicHeaderStrES_NS0_5grid4Ejjjf' for 'sm_75'ptxas info : Function properties for _Z13add_receiversPfPN6common16SeismicHeaderStrES_NS0_5grid4Ejjjf 0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loadsptxas info : Used 30 registers, 496 bytes cmem[0], 16 bytes cmem[2]ptxas info : Compiling entry function '_Z19add_source_withsincPf6float4N6common5gridEf' for 'sm_75'ptxas info : Function properties for _Z19add_source_withsincPf6float4N6common5gridEf 0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loadsptxas info : Used 38 registers, 484 bytes cmem[0]ptxas info : Compiling entry function '_Z10add_sourceP6float26float4N6common5grid4Ef' for 'sm_75'ptxas info : Function properties for _Z10add_sourceP6float26float4N6common5grid4Ef 0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loadsptxas info : Used 11 registers, 484 bytes cmem[0]ptxas info : Compiling entry function '_Z1-add_sourcePf6float4N6common5grid4Ef' for 'sm_75'ptxas info : Function properties for _Z1-add_sourcePf6float4N6common5grid4Ef 0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loadsptxas info : Used 11 registers, 484 bytes cmem[0][100%] Linking CUDA executable ../bin/rtm[100%] Built target rtm |
Future of HPC in energy
The integration of the NVIDIA Energy Samples application with the AWS Energy HPC Orchestrator demonstrates the potential of cloud-native solutions to meet the growing computational demands of the energy industry. The use of pre-optimized cloud-native templates streamlines the process, enabling faster deployment and efficient resource management.
As the energy sector continues to embrace digital transformation, the adoption of such integrated cloud-based systems will be crucial in addressing the increasingly complex computational challenges.
For more information, see AWS Energy HPC Orchestrator and get access to the NVIDIA Energy Samples. Explore AI and HPC for subsurface operations.
Spotlight: Accelerating HPC in Energy with AWS Energy HPC Orchestrator and NVIDIA Energy Samples