



Generative AI has rapidly evolved from text-based models to multimodal capabilities. These models perform tasks like image captioning and visual question answering, reflecting a shift toward more human-like AI. The community is now expanding from text and images to video, opening new possibilities across industries.
Video AI models are poised to revolutionize industries such as robotics, automotive, and retail. In robotics, they enhance autonomous navigation in complex, ever-changing environments, which is vital for sectors like manufacturing and warehouse management. In the automotive industry, video AI is propelling autonomous driving, boosting vehicle perception, safety, and predictive maintenance to improve efficiency.
To build image and video foundation models, developers must curate and preprocess a large amount of training data, tokenize the resulting high-quality data at high fidelity, train or customize pretrained models efficiently and at scale, and then generate high-quality images and videos during inference.
Announcing NVIDIA NeMo for multimodal generative AI
NVIDIA NeMo is an end-to-end platform for developing, customizing, and deploying generative AI models.
NVIDIA just announced the expansion of NeMo to support the end-to-end pipeline for developing multimodal models. NeMo enables you to easily curate high-quality visual data, accelerate training and customization with highly efficient tokenizers and parallelism techniques, and reconstruct high-quality visuals during inference.
Accelerated video and image data curation
High-quality training data ensures high-accuracy results from an AI model. However, developers face various challenges in building data processing pipelines, ranging from scaling to data orchestration.
NeMo Curator streamlines the data curation process, making it easier and faster for you to build multimodal generative AI models. Its out-of-the-box experience minimizes the total cost of ownership (TCO) and accelerates time-to-market.
While working with visuals, organizations can easily reach petabyte-scale data processing. NeMo Curator provides an orchestration pipeline that can load balance on multiple GPUs at each stage of the data curation. As a result, you can reduce video processing time by 7x compared to a naive GPU-based implementation. The scalable pipelines can efficiently process over 100 PB of data, ensuring the seamless handling of large datasets.
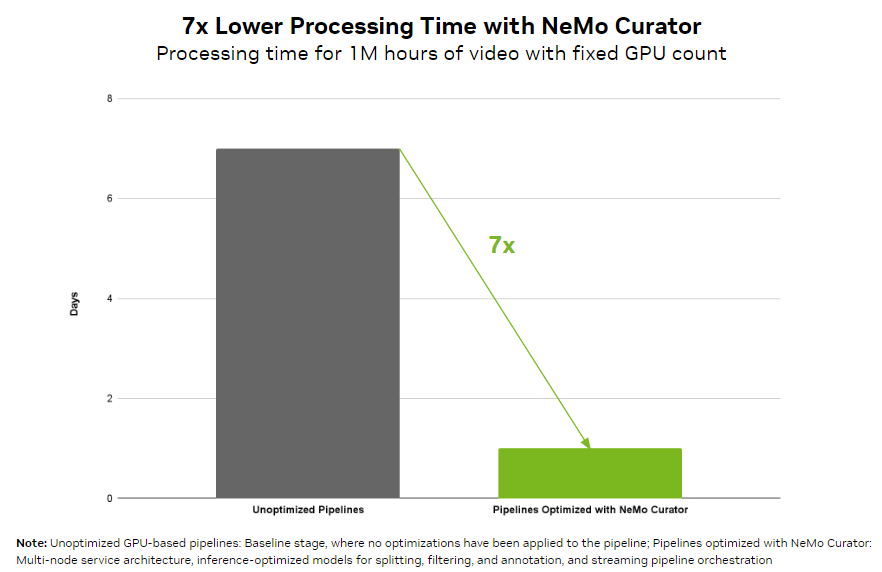
NeMo Curator provides reference video curation models optimized for high-throughput filtering, captioning, and embedding stages to enhance dataset quality, empowering you to create more accurate AI models.
For instance, NeMo Curator uses an optimized captioning model that delivers an order of magnitude throughput improvement compared to unoptimized inference model implementations.
NVIDIA Cosmos tokenizers
Tokenizers map redundant and implicit visual data into compact and semantic tokens, enabling efficient training of large-scale generative models and democratizing their inference on limited computational resources.
Today’s open video and image tokenizers often generate poor data representations, leading to lossy reconstructions, distorted images, and temporally unstable videos and placing a cap on the capability of generative models built on top of the tokenizers.. Inefficient tokenization processes also result in slow encoding and decoding and longer training and inference times, negatively impacting both developer productivity and the user experience.
NVIDIA Cosmos tokenizers are open models that offer superior visual tokenization with exceptionally large compression rates and cutting-edge reconstruction quality across diverse image and video categories.
These tokenizers provide ease of use through a suite of tokenizer standardized models that support vision-language models (VLMs) with discrete latent codes, diffusion models with continuous latent embeddings, and various aspect ratios and resolutions, enabling the efficient management of large-resolution images and videos. This provides you with tools for tokenizing a wide variety of visual input data to build image and video AI models.
Cosmos tokenizer architecture
A Cosmos tokenizer uses a sophisticated encoder-decoder structure designed for high efficiency and effective learning. At its core, it employs 3D causal convolution blocks, which are specialized layers that jointly process spatiotemporal information, and uses causal temporal attention that captures long-range dependencies in data.
The causal structure ensures that the model uses only past and present frames when performing tokenization, avoiding future frames. This is crucial for aligning with the causal nature of many real-world systems, such as those in physical AI or multimodal LLMs.
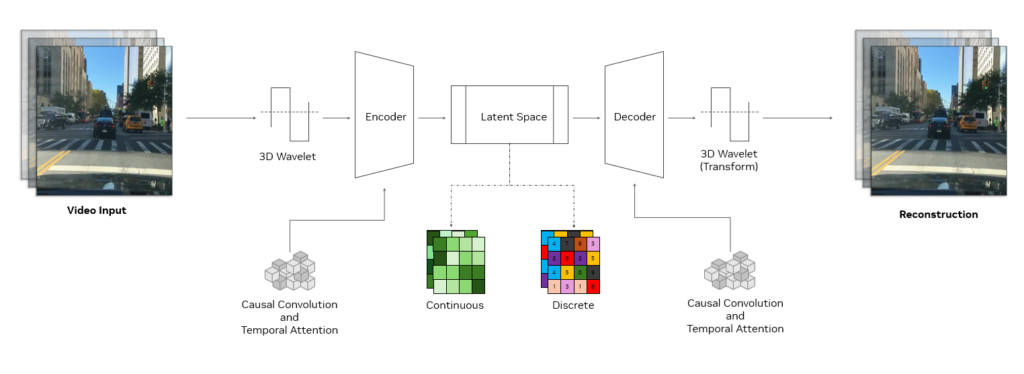
The input is downsampled using 3D wavelets, a signal processing technique that represents pixel information more efficiently. After the data is processed, an inverse wavelet transform reconstructs the original input.
This approach improves learning efficiency, enabling the tokenizer encoder-decoder learnable modules to focus on meaningful features rather than redundant pixel details. The combination of such techniques and its unique training recipe makes the Cosmos tokenizers a cutting-edge architecture for efficient and powerful tokenization.
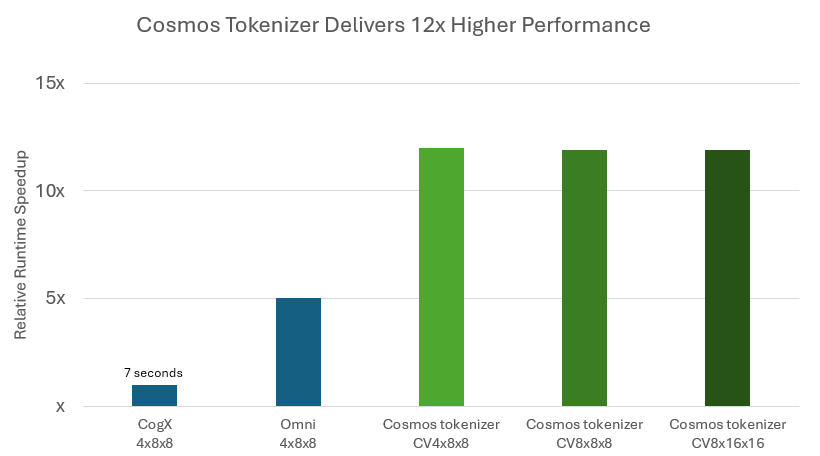
During inference, the Cosmos tokenizers significantly reduce the cost of running the model by delivering up to 12x faster reconstruction compared to leading open-weight tokenizers (Figure 3).
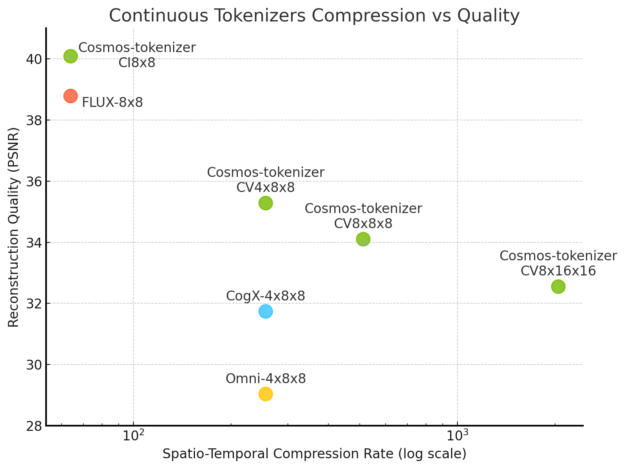
The Cosmos tokenizers also produce high-fidelity images and videos while compressing more than other tokenizers, demonstrating an unprecedented quality-compression trade-off.
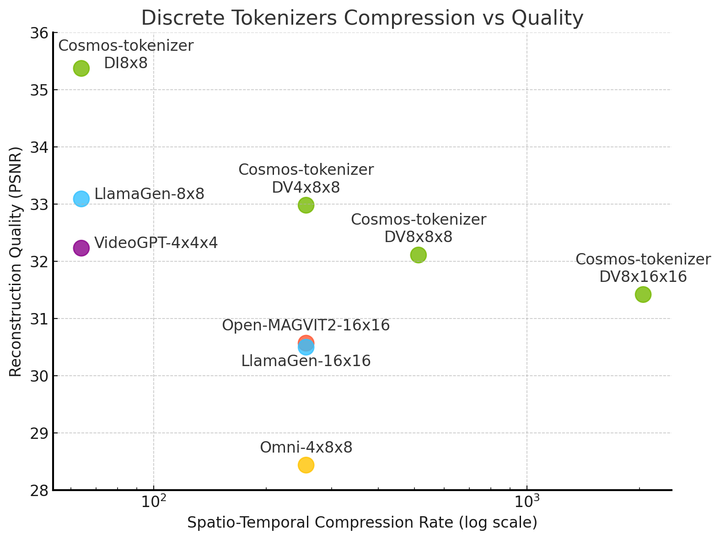
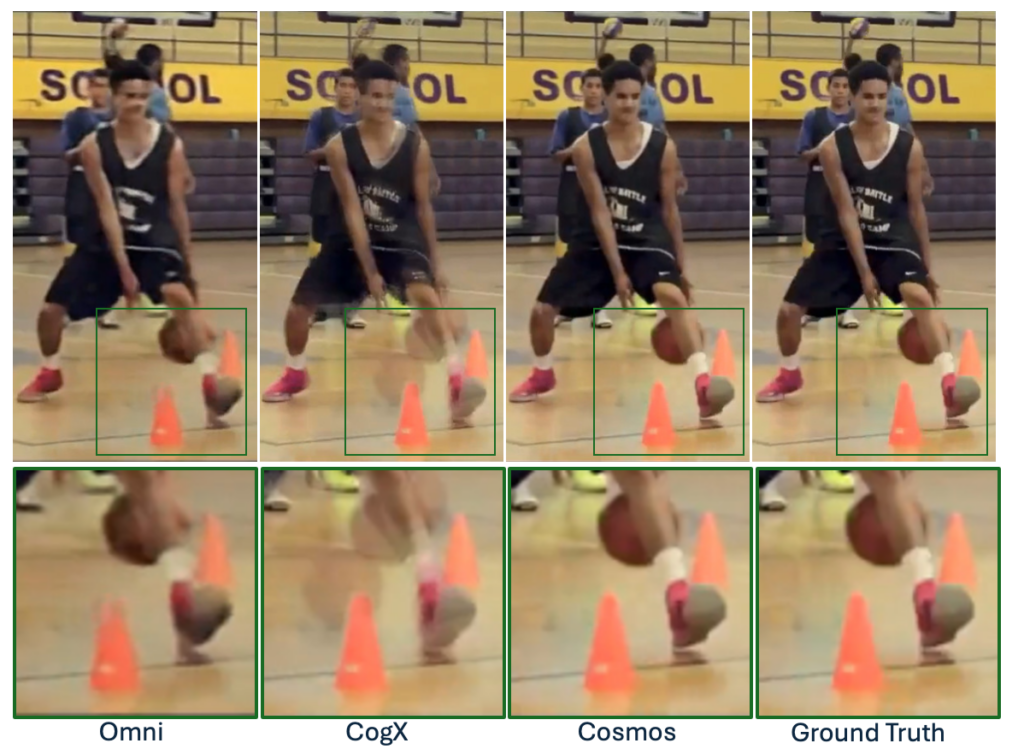
Although the Cosmos tokenizer regenerates from highly compressed tokens, it is capable of creating high-quality images and videos due to an innovative neural network training technique and architecture.
Build Your Own Multimodal Models with NeMo
The expansion of the NVIDIA NeMo platform with at-scale data processing using NeMo Curator and high-quality tokenization and visual reconstruction using the Cosmos tokenizer empowers you to build state-of-the-art multimodal, generative AI models.
Join the waitlist and be notified when NeMo Curator is available. The tokenizer is available now on the /NVIDIA/cosmos-tokenizer GitHub repo and Hugging Face.
State-of-the-Art Multimodal Generative AI Model Development with NVIDIA NeMo