


5G global connections numbered nearly 2 billion earlier this year, and are projected to reach 7.7 billion by 2028. While 5G has delivered faster speeds, higher capacity, and improved latency, particularly for video and data traffic, the initial promise of creating new revenues for network operators has remained elusive.
Most mobile applications are now routed to the cloud. At the same time, radio access network (RAN) and packet core solutions based on traditional designs continue to improve incrementally with software enhancements and more efficient hardware. These single-purpose systems running traditional voice, data, and video workloads aren’t significantly increasing average revenue per user for telecom companies. Instead, these systems are primarily enabling connectivity and viewed as operating expenditures, which reduces the return on investment. However, this approach is about to change.
The emergence of ChatGPT and rapid large language model (LLM) innovation provide a first glimpse at a new type of application that requires accelerated computing. This demands a different kind of multipurpose network to optimize AI and generative AI workloads. Initially, AI network deployments were focused on heavy training workloads that were centralized and required large data centers. Early LLM inference has also been mostly centralized and bound tightly to the training efforts, resulting in more of the same traffic motion from edge to cloud.
Vision language models (VLMs) and small language models (SLMs), as well as enhanced efficiency of LLM inference, lend well to a distributed architecture spread across networks that bring generative AI models closer to data. The evolution of generative AI towards agentic AI and multimodal AI will demand closer alignment of inferencing to network endpoints, as enterprises need data localization, security, and guaranteed quality of service (QoS). These requirements are already delivered by today’s telecom networks.
This post explains the need for AI-native network infrastructure and presents key implications of and opportunities for meeting the demands of AI workloads in a telco network.
Balancing AI inference traffic with legacy workloads
Moving from a centralized compute architecture targeted at LLM training to a highly distributed inference approach for generative AI will have profound effects on future networks. With an increase in SLM, VLM, and LLM inference traffic, more requests with data flow in the network. End devices will evolve to intercept some requests, but are limited by on-device compute, memory, and power.
Sending all network traffic to the cloud, as traditional apps do, is problematic, as generative AI models carry data to generate unique and real-time responses. Adding up the volume of expected consumer and enterprise inference requests with internal models on the network results in a busy data pipeline.
Cases are emerging for multimodal requests that need adaptive routing to improve throughput and latency. Other requirements that will affect data movement are user privacy, sovereignty, and security, including the data allowed through packet core and UPF.
This is a perfect opportunity for telecom companies, as their wireless networks and compute clusters are highly distributed, and available in many geographic locations. If telecom companies can balance critical legacy workloads and new AI inference traffic, then the application generates revenue. This approach has started working in LLM training, and generative AI inference is logically the next area telcos should focus on for monetization opportunities.
Supporting agile inference services
NVIDIA and the AI ecosystem are fully invested in creating lighter and more agile inference services. These are built as containers that can run anywhere, and they can be load balanced, scheduled, and combined in diverse ways. Deployable containers enable generative AI models to be closer to data and leverage retrieval-augmented generation (RAG). This will be increasingly important as SLMs, VLMs, and multimodel models are created and agentic workflows become prevalent.
A network can support AI containers almost anywhere. The AI agents and smaller models will lead to a new type of LLM, or model-based routing, where model weights and network insights are used to determine which model is needed where and how to load balance the network traffic to these models to prevent blocks and oversubscription.
Current networks, especially at the edge, are not built for this adaptive routing of AI traffic.
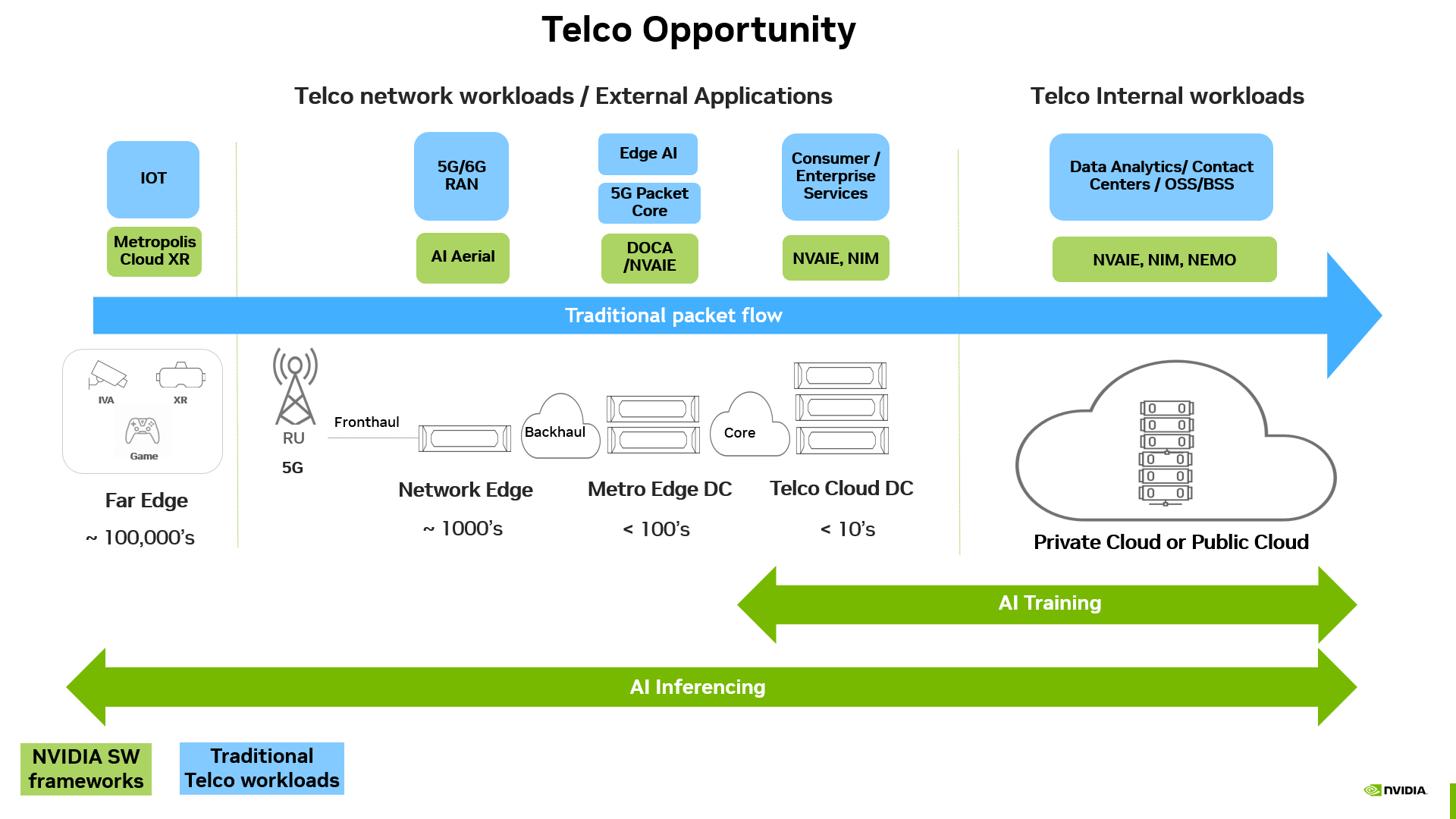
AI-native network infrastructure
Telecom networks today often use single-purpose and hardware-optimized solutions for each part of the network. The Distributed Unit (DU) and Centralized Unit (CU) have a box, the firewall has a box, the User Plane Function (UPF) has a box, and so on. Connecting these units are network switches and a fabric that’s not optimized in most cases.
Using software-defined workloads is the first step to solve this problem. If every application can be software-defined, then applications can run in a container that has been optimized and can be loaded anywhere.
The generative AI landscape and the emergence of LLMs require a full-stack accelerated compute platform as the foundation. This AI-native network infrastructure can scale and be well utilized by many industry standard applications. In theory, the same infrastructure can host any software-defined application and be shared dynamically, based on demand to create future networks that are AI-native, programmable, and multipurpose, including:
- Low power, high-performance energy efficient CPU (usually ARM-based) for serial, virtualized, and tenant-based applications.
- High-power accelerator for parallel, vector, and matrix-based applications (usually a GPU).
- Low-power accelerator of traffic to handle interrupt-driven and packet shaping use cases (usually a DPU).
Nearly any software-defined application can be optimized with a capable software framework across CPU, GPU, and DPU.
The second step is to ensure the optimization of the network routing and fabric. Additional network security and optimization are needed inside the data pipeline, not on traditional compute architecture. Network fabric must be programmable to adapt to AI or non-AI workloads in real time, whether to support east-west traffic in an AI cluster or traffic to a firewall or storage device. This fabric must be capable of adaptively routing and load balancing LLM inference requests.
Much of this work is already happening with key independent software vendors (ISVs), firewall vendors, packet core providers, and other ecosystem members taking a software-defined approach to meet the demands of their telecom customers.
Higher performance and new revenue opportunities
AI inference is moving at an extremely fast pace. Telecom companies must address the new demands of AI traffic, coupled with demands to maximize compute infrastructure utilization and increase revenues.
By using the best tools for each task, telecom companies can achieve significantly higher performance per watt, while not compromising on programmability and multi-use case support. Running software-defined legacy workloads with new AI workloads on the same RAN infrastructure unlocks new revenue opportunities.
Telecom companies looking to monetize their infrastructure can take any of the following steps:
- Enhance sections of or all network fabric with lower power CPUs and capable DPUs. This is regardless of AI, and follows a reference architecture deployed successfully by cloud service providers and large telecom companies in the APAC region.
- Select edge locations and seed them with AI capable accelerated compute infrastructure. This is not a large investment, and enables telecom companies to target clients and use cases ready to get AI-powered solutions. These will benefit from being 5G/6G-ready, and could be used for AI today.
- Build an accelerated compute-based cluster in the data center for both internal and external use cases, using data from both internal teams and client use cases.
Summary
As LLM-powered applications and AI workloads accelerate at unprecedented speed, telecom companies need to rethink networks to manage AI traffic. NVIDIA is working across the telecom ecosystem with software providers and partners to map AI workloads, migrate to a software-defined model, and optimize on accelerated compute architecture. NVIDIA is also working closely with telecom companies to share global progress, collaborate on innovation projects, and welcome new partners to join the journey.
Learn about NVIDIA Enterprise Reference Architectures, including AI-optimized networking.
Transforming Telecom Networks to Manage and Optimize AI Workloads